企业网站优化官网seo服务合同
目录
数据聚合
Bucket示例
Metric示例
RestAPI实现聚合
自动补全
使用拼音分词
自定义分词器
实现自动补全
RestAPI实现自动补全功能
数据同步
同步调用
异步通知
监听binlog
数据聚合
聚合可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
- 桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
- 度量 (Metric)聚合:用以计算一些值,比如: 最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求成max、min、avg、sum等
- 管道(pipeline)聚合:其他聚合的结果为基础做聚合
需要注意的是,聚合的数据不能被分词。
Bucket示例
根据品牌名称做聚合
#聚合功能
GET /hotel/_search
{"size": 0,// 展示的文档个数"aggs": {// 聚合"brandAgg": { //聚合名称"terms": { //聚合方式"field": "brand", "order": {"_count": "desc"},"size": 10 //结果展示}}}
}
默认情况加Bucket聚合是对所有文档进行聚合,这样对内存消耗较大,因此我们可以通过query指定聚合范围
GET /hotel/_search
{"query": {"range": {"price": {"gte": 100,"lte": 200}}}, "size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 10}}}
}
Metric示例
对每个品牌的评分进行聚合。
GET /hotel/_search
{"size": 0,"aggs": {"brandAggs": {"terms": {"field": "brand","size": 10},"aggs": {"score_stats": {"stats": {"field": "score"}}}}}
}
如果需要对评分做一个排序,实际上是对桶聚合排序
GET /hotel/_search
{"size": 0,"aggs": {"brandAggs": {"terms": {"field": "brand","size": 10,"order": {"score_stats.avg": "desc"}},"aggs": {"score_stats": {"stats": {"field": "score"}}}}}
}
RestAPI实现聚合
@Testpublic void testAggregation() throws Exception {SearchRequest request = new SearchRequest("hotel");//不需要接收文档request.source().size(0);request.source().aggregation(//聚合名称AggregationBuilders.terms("brandAgg")//聚合字段.field("brand")//取值.size(10));SearchResponse response = client.search(request, RequestOptions.DEFAULT);//结果解析Aggregations aggregations = response.getAggregations();Terms brand_agg = aggregations.get("brandAgg");List<? extends Terms.Bucket> buckets = brand_agg.getBuckets();for (Terms.Bucket bucket : buckets) {String brand = bucket.getKeyAsString();System.out.println(brand);}}解析结果根据ES的返回内容依次获取就好

自动补全
所谓自动补全,是指输入部分内容会展示对应的相关内容

使用拼音分词
如果要实现根据字母补全内容,那么就需要对文档进行拼音分词。下载对应版本的拼音分词插件
GitHub - medcl/elasticsearch-analysis-pinyin: This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
并放入es的插件目录下
GET /_analyze
{"text": ["我正在学分布式搜索"],"analyzer": "pinyin"
}
默认的拼音分词器只会单个汉字的拼音与整句的拼音首字母分词。并不能满足我们的业务需求。因此我们需要自定义分词器。
自定义分词器
elasticsearch中分词器的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条 (term)。例如keyword,就是不分词;还有ik_smart。
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等

自定义的分词器只能在创建索引库的时候指定
PUT /test
{"settings": {"analysis":{"analyzer": { // 自定义分词器"my_analyzer": {// 分词器名称"tokenizer":"ik_max_word","filter":"py"}},"filter": { // 自定义tokenizer filter"py":{ // 过滤器名称"type":"pinyin",// 过滤器类型,这里是pinyin"keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term" : true,"none_chinese_pinyin_tokenize":false}}}}
}拼音分词器只能创建倒排索引的时候使用而不适合在搜索的时候使用。

因此在创建索引库的时候,可以指定搜索分词器
PUT /test
{"settings": {"analysis":{"analyzer": { // 自定义分词器"my_analyzer": {// 分词器名称"tokenizer":"ik_max_word","filter":"py"}},"filter": { // 自定义tokenizer filter"py":{ // 过滤器名称//.....}}}},"mappings":{"properties": {"name" :{"type": "text","analyzer":"my_analyzer","search_analyzer": "ik_smart"}}}
}实现自动补全
ES提供completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了补全查询效率,对文档中字段有一定约束
- 参与补全的必须是completion类型
- 字段的内容一般是用来补全的多个词条形成的数组
PUT /test
{"mappings":{"properties":{"title":{"type":"completion"}}}
}POST /test/_doc
{"title":["Sony","WH-1000XM3"]
}POST /test/_doc
{"title":["SK-II","PITERA"]
}POST /test/_doc
{"title":["Niotendo","switch"]
}# 自动补全查询
GET /test/_search
{"suggest": {"title_suggest":{"text":"s", "completion":{"field":"title","skip_duplicates": true,"size": 10}}}
}
RestAPI实现自动补全功能

@Testpublic void testSuggest() throws Exception {SearchRequest request = new SearchRequest("hotel");request.source().suggest(new SuggestBuilder().addSuggestion("suggestions",//自定义,后面解析响应的时候也输入这个值就好SuggestBuilders.completionSuggestion("suggestion").prefix("bj").skipDuplicates(true).size(10)));SearchResponse response = client.search(request, RequestOptions.DEFAULT);CompletionSuggestion suggestions = response.getSuggest().getSuggestion("suggestions");for (CompletionSuggestion.Entry.Option option : suggestions.getOptions()) {String test = option.getText().string();System.out.println(test);}}数据同步
ES一般和数据库联合使用,ES的数据来源于数据库,但是数据库的内容并不是一成不变的,因此ES与数据库就存在了数据同步问题。
同步调用
当客户端发起请求后,首先数据库进行修改,修改完成后去调用搜索服务的更新ES接口,等ES更新完成后返回结果给保存数据库的服务,再返回给客户端

优点:实现简单
缺点:
- 代码耦合,在更新完数据库后需要添加调用ES更新接口的代码
- 耗时增加,性能下降
异步通知

优点:耦合度低,实现难度一般
缺点:依赖MQ的可靠性
监听binlog
数据库可以开启binlog功能。当数据库发生CURD时,binlog会发生改变,由canal通知ES服务修改ES数据。
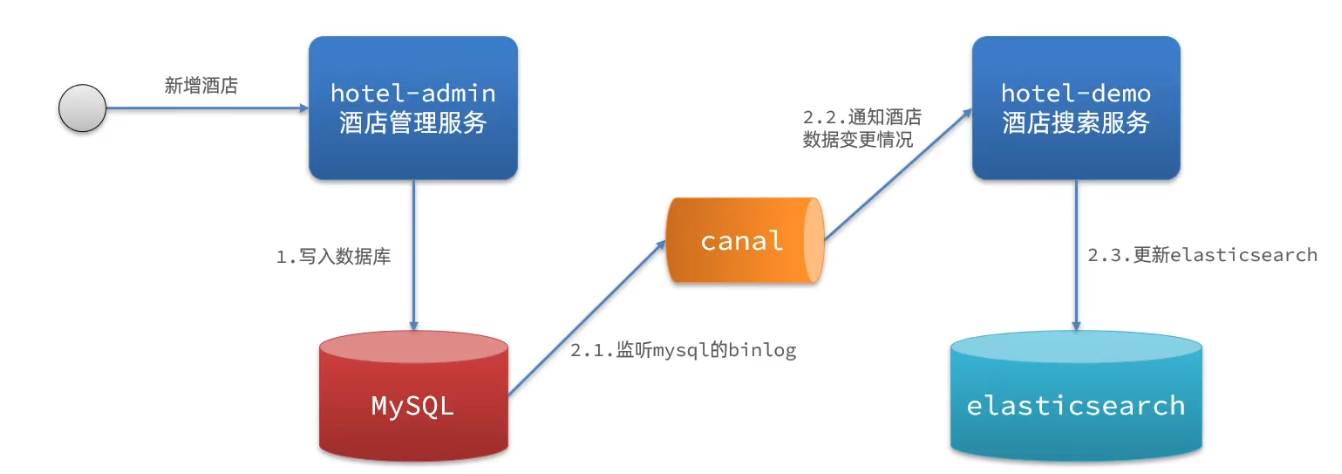
优点:完全解耦
缺点:开启binlog增加数据库负担。实现复杂度高