沈阳开发网站公司seo提升排名
一、无监督相关(聚类、异常检测)
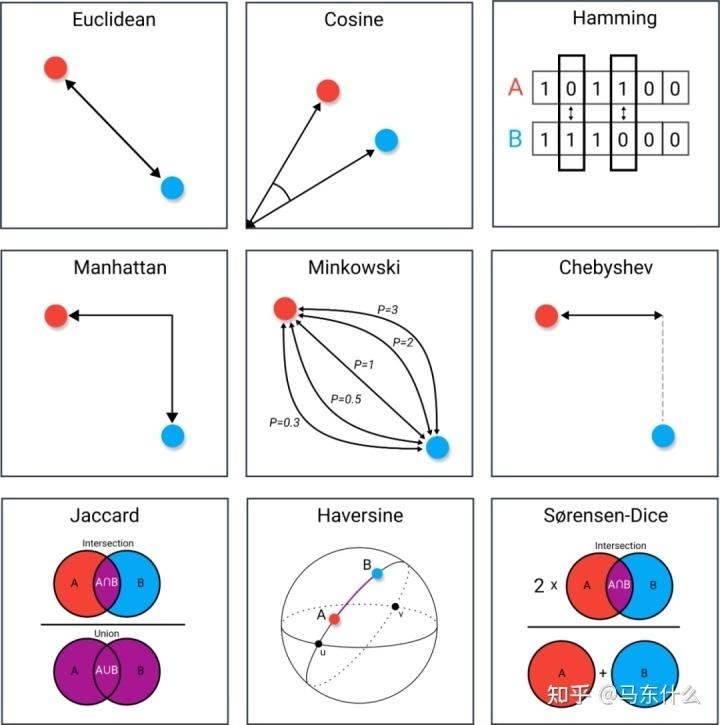
1、常见的距离度量方法有哪些?写一下距离计算公式。
1)连续数据的距离计算:
闵可夫斯基距离家族:

当p = 1时,为曼哈顿距离;p= 2时,为欧式距离;p ->∞时,就是切比雪夫距离。
余弦距离:
![]()
其中,A 和B是要比较的两个向量,⋅ 表示向量的点积(内积),∥A∥ 和 ∥B∥ 分别表示向量 A 和 B的欧几里德范数(也称为 L2 范数)。余弦距离的值范围在[0,2],取值越小表示两个向量越相似,取值越大表示两个向量越不相似。如果两个向量方向相同,则余弦距离为 0,表示完全相似;如果两个向量方向相反,则余弦距离为 2,表示完全不相似。请注意,有时也可以用余弦相似性(Cosine Similarity)来衡量向量的相似性,它是余弦距离的补数,即1−Cosine Distance。余弦相似性的取值范围在 [-1, 1],取值越大表示两个向量越相似,取值越小表示越不相似。
2)离散数据的距离计算
杰卡尔德(Jaccard)距离:A,B集合的交集/A,B集合的并集
汉明距离:表示两个等长字符串在对应位置上不同字符的数目
2、常见的聚类算法有哪些?
主要有基于划分、基于密度、基于网络、层次聚类等,除此之外聚类和其他领域也有很多结合形成的交叉领域比如半监督聚类、深度聚类、集成聚类等。
3、Kmeans的原理是什么?
Kmeans是一种基于划分的聚类,中心思想是类内距离尽量小,类间距离尽量大,主要算法过程如下:
- 初始K个质心,作为初始的K个簇的中心点,K为人工设定的超参数;
- 所有样本点n分别计算和K个质心的距离,这里的距离是人工定义的可以是不同距离计算方法,每个样本点和k个质心中最近的质心划分为1类簇;
- 重新计算质心,方法是针对簇进行聚合计算,kmeans中使用简单平均的方法进行聚合计算,也可以使用中位数等方式进行计算;
- 重复上述过程直到达到预定的迭代次数或质心不再发生明显变化。
- kmeans的损失函数是:

其中,||xi - cj|| 表示数据点 xi 到簇中心 cj 的欧氏距离,I(condition) 是一个指示函数,当 condition 成立时为 1,否则为 0。J越小,说明样本聚合程度越高。
4、Kmeans的初始点怎么选择,不同的初始点选择有哪些缺陷?该怎么解决?
- 随机初始化:随机选取K个样本点作为初始质心,缺陷在于如果选择到的质心距离很接近落在同个簇内,则迭代的结果可能比较差,因为最终迭代出来的质心点会落在簇内。最理想的状态是K个质心正好是K个簇,由于随机初始化的随机性,可以考虑多次进行随机初始化,选择聚合结果最优的一次。
- 随机分取初始化:即将所有样本点随机赋予1个簇的编号,则所有样本点最后会有K个编号,然后进行组平均,即对于同一个簇的样本进行平均得到初始化质心。相对于随机初始化,初始化质心会更鲁棒一些,但是仍旧存在随机初始化的缺陷,仅仅是缓解。
5、Kmeans聚的是特征还是样本?特征的距离如何计算?
一般情况下是对样本聚类,如果对特征聚类则处理方式也简单,对原始的输出进行转置。其目的和做相关系数类似,如果两个特征高度相关,例如收入和资产水平,则两个特征的距离相对较小,但是一般不可行,因为转置后维度很高,例如有100万个样本则有100万的维度,计算上不现实,高维数据的距离度量也是无效的,不如直接计算相关系数。
6、Kmeans如何调优?
- 初始化策略调参
- k的大小调参,手工方法,手肘法为代表
- 数据归一化和异常样本的处理
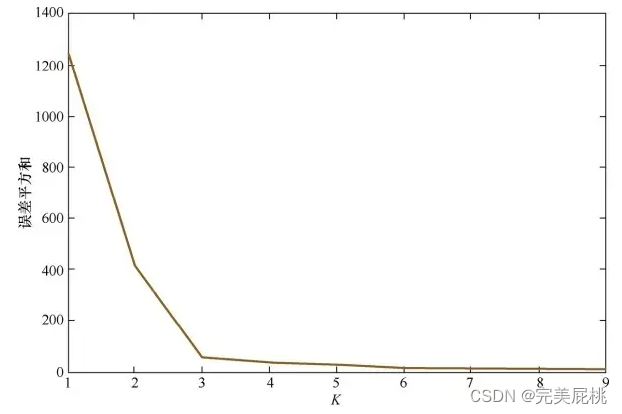
7、介绍一下手肘法。
手肘法纵轴是聚类效果的评估指标,根据具体的问题而定,如果聚类是作为单独的任务存在则使用SSE(损失函数)或轮廓系数这类的metric作为纵坐标,然后找到metric最好且k最小的结果,对应的k为最终的选择。手肘法自动化时,只需计算k = n 和 k = n+1之间的斜率,当斜率n和n-1,斜率n+1和斜率n,斜率n+2和斜率n+1的差值均小于固定阈值时即可停止。
8、kmeans的缺点如何解决?
- 对异常样本很敏感,簇心会因为异常样本被拉得很远。异常样本是指在某些维度上取值特别大或者特别小的样本,欧式距离中默认所有特征是相互独立的,异常样本会产生影响。解决方法是做好预处理,将异常样本剔除或者修正。
- K值很难确定。解决方法是针对k调参。
- 只能拟合球形簇,对于流形簇等不规则簇可能存在簇重叠的问题,效果差。这种情况可能不再适用于Kmeans算法,考虑换算法。
- 无法处理离散特征,缺失特征。
- 无法保证全局最优。解决方法是跑多次,取不同的局部最优里的最优。