个人网站报价竞价是什么工作
文章目录
- SequenceFile、元数据操作与MapReduce单词计数
- 一、实验目标
- 二、实验要求
- 三、实验内容
- 四、实验步骤
- 附:系列文章
SequenceFile、元数据操作与MapReduce单词计数
一、实验目标
- 熟练掌握hadoop操作指令及HDFS命令行接口
- 掌握HDFS SequenceFile读写操作
- 掌握MapReduce单词计数操作
- 熟练掌握查询文件状态信息和目录下所有文件的元数据信息的方法
二、实验要求
- 给出主要实验步骤成功的效果截图。
- 要求分别在本地和集群测试,给出测试效果截图
- 对本次实验工作进行全面的总结。
- 完成实验内容后,实验报告文件名加上学号姓名。
- 涉及的文件名、类名自拟,要求体现本人学号或姓名信息,涉及的文件内容自拟。
三、实验内容
-
SequenceFile写操作,实现效果如下图所示。


-
SequenceFile读操作,实现效果如下图所示。


-
输出一个目录下多个文件的文件状态和元数据信息。


-
使用mapreduce编程,自拟文件名和文件内容,完成对该文件的单词计数,实现效果参考下图。

四、实验步骤
1.SequenceFile写操作
程序设计
package hadoop;import java.io.*;
import java.net.URI;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.util.*;@SuppressWarnings("unused")
public class SeqFileWrite {static Configuration conf = new Configuration();static String url = "hdfs://master:9000/seqfile.txt";static String[] data = {"a,b,c", "a,e,f", "a,j,k"};public static void main(String[] args) throws IOException{FileSystem fs = FileSystem.get(URI.create(url), conf);Path path = new Path(url);IntWritable key = new IntWritable();Text text = new Text();@SuppressWarnings("deprecation")SequenceFile.Writer w = SequenceFile.createWriter(fs, conf, path, IntWritable.class, Text.class);for(int i=0; i<10; i++){key.set(10-i);text.set(data[i%data.length]);w.append(key, text);}IOUtils.closeStream(w);}
}
程序分析
这是一个使用Hadoop的SequenceFile编写程序,它可以将数据写入到一个SeqFile中。SeqFile是Hadoop中的一种二进制文件格式,它能够高效地储存大量的键值对数据,并支持高效地随机访问。
在程序中,首先定义了一个静态的Configuration对象和一个静态的URL字符串url,用于指定数据文件的位置。然后定义了一个包含若干数据字符串的data数组。
在main()方法中,通过调用FileSystem.get()方法获取一个文件系统对象fs,并通过指定URL字符串和Configuration对象来实现。然后定义一个Path对象指定数据文件的路径。
接下来定义一个IntWritable对象key和一个Text对象text,用于储存键和值。打开文件并创建一个SequenceFile.Writer对象w,用于向SeqFile中写入数据。
通过for循环遍历数据,将数据写入到SeqFile中,并通过IOUtils.closeStream()方法关闭写入流。
总的来说,这个程序是一个简单的SeqFile写入例子,它可以帮助初学者了解SeqFile的使用方法。
运行结果

2.SequenceFile读操作
程序设计
package hadoop;import java.io.*;
import java.net.URI;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.util.*;public class SeqFileRead {static Configuration conf = new Configuration();static String url = "hdfs://master:9000/seqfile.txt";public static void main(String[] args) throws IOException{FileSystem fs = FileSystem.get(URI.create(url), conf);Path path = new Path(url);@SuppressWarnings("deprecation")SequenceFile.Reader r = new SequenceFile.Reader(fs, path, conf);Writable keyclass = (Writable)ReflectionUtils.newInstance(r.getKeyClass(), conf);Writable valueclass = (Writable)ReflectionUtils.newInstance(r.getValueClass(), conf);while(r.next(keyclass, valueclass)){System.out.println("key:" + keyclass);System.out.println("valueL:" + valueclass);System.out.println("position:" + r.getPosition());}IOUtils.closeStream(r);}
}
程序分析
这是一个使用Hadoop的SequenceFile读取程序,它可以从指定的SeqFile中读取数据并输出到控制台上。
在程序中,首先定义了一个静态的Configuration对象和一个静态的URL字符串url,用于指定数据文件的位置。
在main()方法中,通过调用FileSystem.get()方法获取一个文件系统对象fs,并通过指定URL字符串和Configuration对象来实现。然后定义一个Path对象指定数据文件的路径。
接下来打开文件并创建一个SequenceFile.Reader对象r,用于从SeqFile中读取数据。通过ReflectionUtils.newInstance()方法动态生成Writable类型的对象实例。然后在while循环中,通过r.next()方法读取下一个键值对,并输出到控制台上。
最后通过IOUtils.closeStream()方法关闭读取流。
总的来说,这个程序是一个简单的SeqFile读取例子,它可以帮助初学者了解SeqFile的读取方法和Writable对象的动态生成方法。
运行结果

3.读取文件元信息
程序设计
package hadoop;import java.io.IOException;
import java.net.URI;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;public class FileStatus {public static void main(String[] args){Configuration conf = new Configuration();conf.set("fs.DefailtFS", "hdfs://master:9000/");FileSystem fs = null;Path path[] = new Path[args.length];for(int i=0; i<path.length; i++){path[i] = new Path(args[i]);}try{fs = FileSystem.get(URI.create(args[0]), conf);org.apache.hadoop.fs.FileStatus[] filestatus = fs.listStatus(path);Path listPaths[]=FileUtil.stat2Paths(filestatus);for(Path p:listPaths){System.out.println(p);System.out.println(p.getName());String ps = p.toString();FileSystem fs2 = FileSystem.get(URI.create(ps),conf);org.apache.hadoop.fs.FileStatus[] filestatus2 = fs2.listStatus(p);for(int i=0; i<filestatus.length;i++){System.out.println(filestatus[i]);}}}catch(IOException e){e.printStackTrace();}}}
程序分析
这是一个使用Hadoop的FileStatus获取指定文件夹中的文件状态信息的程序。
在程序中,首先定义了一个Configuration对象conf,并设置default file system的URL为"hdfs://master:9000/"。然后通过FileSystem.get()方法获取一个文件系统对象fs。
在main()方法中,通过for循环依次处理传入的参数,将其转换为Path对象并存储在数组path[]中。
在try语句块中,通过fs.listStatus()方法获取指定文件夹的文件状态信息,存储在数组filestatus[]中。然后通过FileUtil.stat2Paths()方法将filestatus[]转换为Path类型的数组listPaths[]。
接下来遍历listPaths[]数组,分别输出路径和文件名,并再次调用FileSystem.get()方法获取一个新的文件系统对象fs2,用于获取指定路径下的文件状态信息。通过fs2.listStatus()方法获取指定路径下的文件状态信息,存储在数组filestatus2[]中,并将其循环输出到控制台上。
最后通过catch(IOException e)方法捕获异常并输出错误信息。
总的来说,这个程序是一个简单的使用Hadoop的FileStatus获取文件状态信息的例子,可以帮助初学者了解Hadoop中FileStatus的使用方法。
运行结果

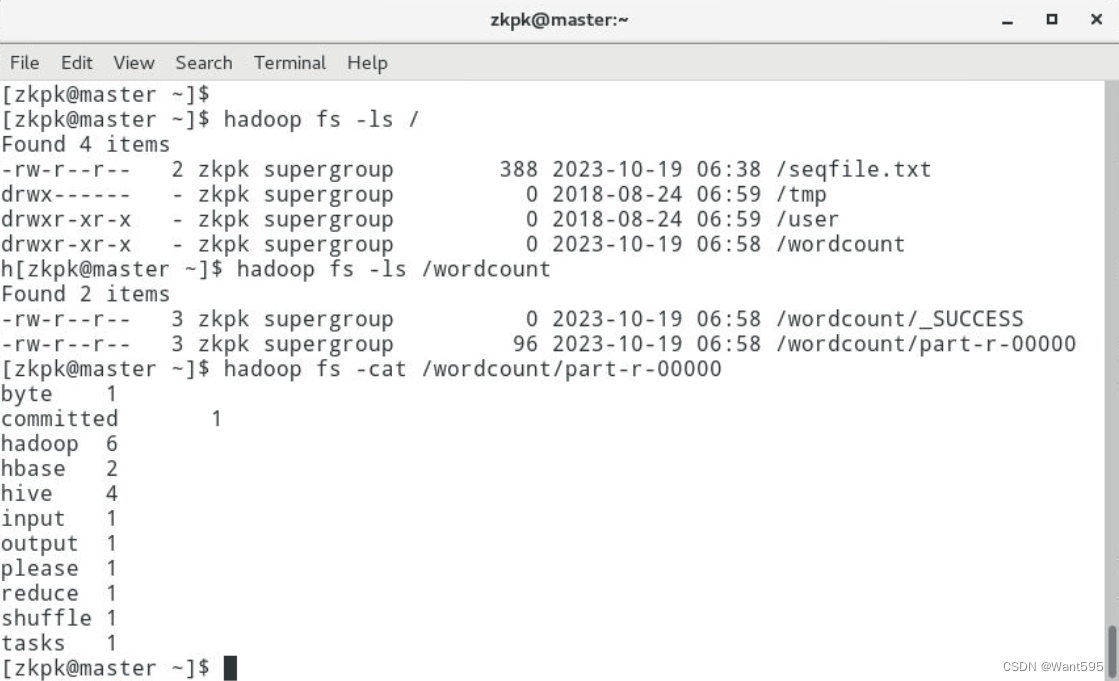
4.单词计数
程序设计
Map类:
package hadoop;
import java.io.IOException;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.io.*;public class Map extends Mapper<Object, Text, Text, IntWritable>{protected void map(Object key, Text value, Context context) throws IOException, InterruptedException{String [] lines = value.toString().split(" ");for(String word : lines){context.write(new Text(word), new IntWritable(1));}}}
Reduce类:
package hadoop;
import java.io.IOException;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer;public class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException{int sum = 0;for (IntWritable count:values){sum = sum + count.get();}context.write(key, new IntWritable(sum));}}
主函数:
package hadoop;import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
import org.apache.hadoop.mapreduce.*;import java.io.IOException;import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.fs.*;public class WordMain {@SuppressWarnings("deprecation")public static void main(String[] args) throws IOException,ClassNotFoundException,InterruptedException{if(args.length != 2 || args == null){System.out.println("please input current Path");System.exit(0);}Configuration conf = new Configuration();Job job = new Job(conf, WordMain.class.getSimpleName());job.setJarByClass(WordMain.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);job.waitForCompletion(true);}
}
运行结果
附:系列文章
| 实验 | 文章目录 | 直达链接 |
|---|---|---|
| 实验01 | Hadoop安装部署 | https://want595.blog.csdn.net/article/details/132767284 |
| 实验02 | HDFS常用shell命令 | https://want595.blog.csdn.net/article/details/132863345 |
| 实验03 | Hadoop读取文件 | https://want595.blog.csdn.net/article/details/132912077 |
| 实验04 | HDFS文件创建与写入 | https://want595.blog.csdn.net/article/details/133168180 |
| 实验05 | HDFS目录与文件的创建删除与查询操作 | https://want595.blog.csdn.net/article/details/133168734 |