做企业网站需要买什么资料百度招聘官网
使用 pgvector 为 HNSW 并行构建索引

Postgres 最受欢迎的向量搜索扩展 pgvector 最近实现了并行索引构建功能,这将分层可导航小世界 (HNSW) 索引构建时间显著提高了 30 倍。
祝贺 Andrew Kane 和 pgvector 的贡献者发布此版本,这巩固了 Postgres 作为最佳向量搜索数据库之一的地位,并允许您充分利用数据库的功能来构建索引。
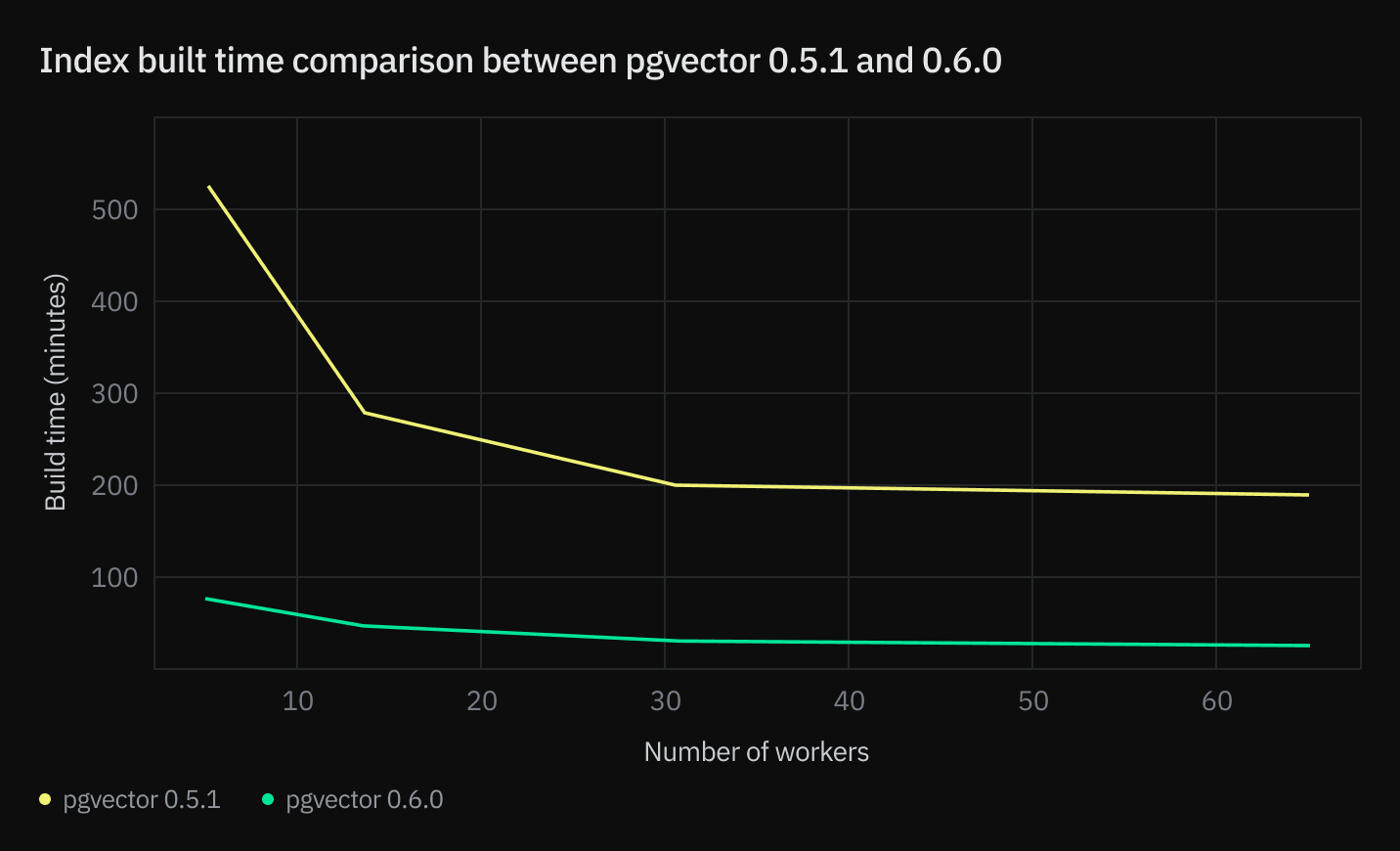
在 64 vCPU、512GB RAM 实例上使用包含 1,536 维向量的 10M 数据集运行测试。
Pgvector 是 Postgres 最受欢迎的向量相似性搜索扩展。向量搜索对于语义搜索和检索增强生成 (RAG) 应用程序越来越重要,可增强大型语言模型 (LLM) 的长期记忆。
在语义搜索和 RAG 用例中,数据库包含 LLM 未接受过训练的知识库,这些知识库被拆分成一系列文本或块。每个文本都保存在一行中,并与嵌入模型(例如 OpenAI 的 ada-embedding-002 或 Mistral-AI 的 mistral-embed ) 生成的向量相关联。
然后使用向量搜索来查找与查询向量最相似(更接近)的文本。这是通过将查询向量与数据库中的每一行进行比较来实现的,这使得向量搜索难以扩展。这就是为什么 pgvector 实施 近似最近邻 (ANN) 算法(或索引)的原因,该算法在数据库的子集上进行向量搜索,以避免冗长的连续扫描。
最有效的 ANN 算法之一是分层可导航小世界 (HNSW) 索引。其基于图形和多层的特性专为数十亿行向量搜索而设计。这使得 HNSW 在规模上极其快速和高效,并且是向量存储市场中最受欢迎的索引之一。
HNSW 首次由 Yu A Malkov 和 Dmitry A. Yashunin 在题为《使用分层可导航小世界图进行高效、稳健的近似最近邻搜索》的论文中提出。
HNSW 是一种基于图的索引高维数据的方法。它构建了一个图的层次结构,其中每一层都是前一层的子集,因此时间复杂度为 O(log(rows)) 。在搜索过程中,它会浏览这些图以快速找到最近的邻居。

尽管 HNSW 指数快速而高效,但它也存在两个缺点:
1. 内存 :该索引所需的内存明显多于其他索引,例如倒排文件索引 (IVFFlat)。您可以通过拥有更大的数据库实例来解决内存问题。但是,如果您使用独立的 Postgres(例如 AWS RDS),您会发现自己处于仅为索引构建而过度配置的情况。但是,借助 Neon 扩展功能,您可以扩展、构建 HNSW 索引,然后缩减规模以节省成本。
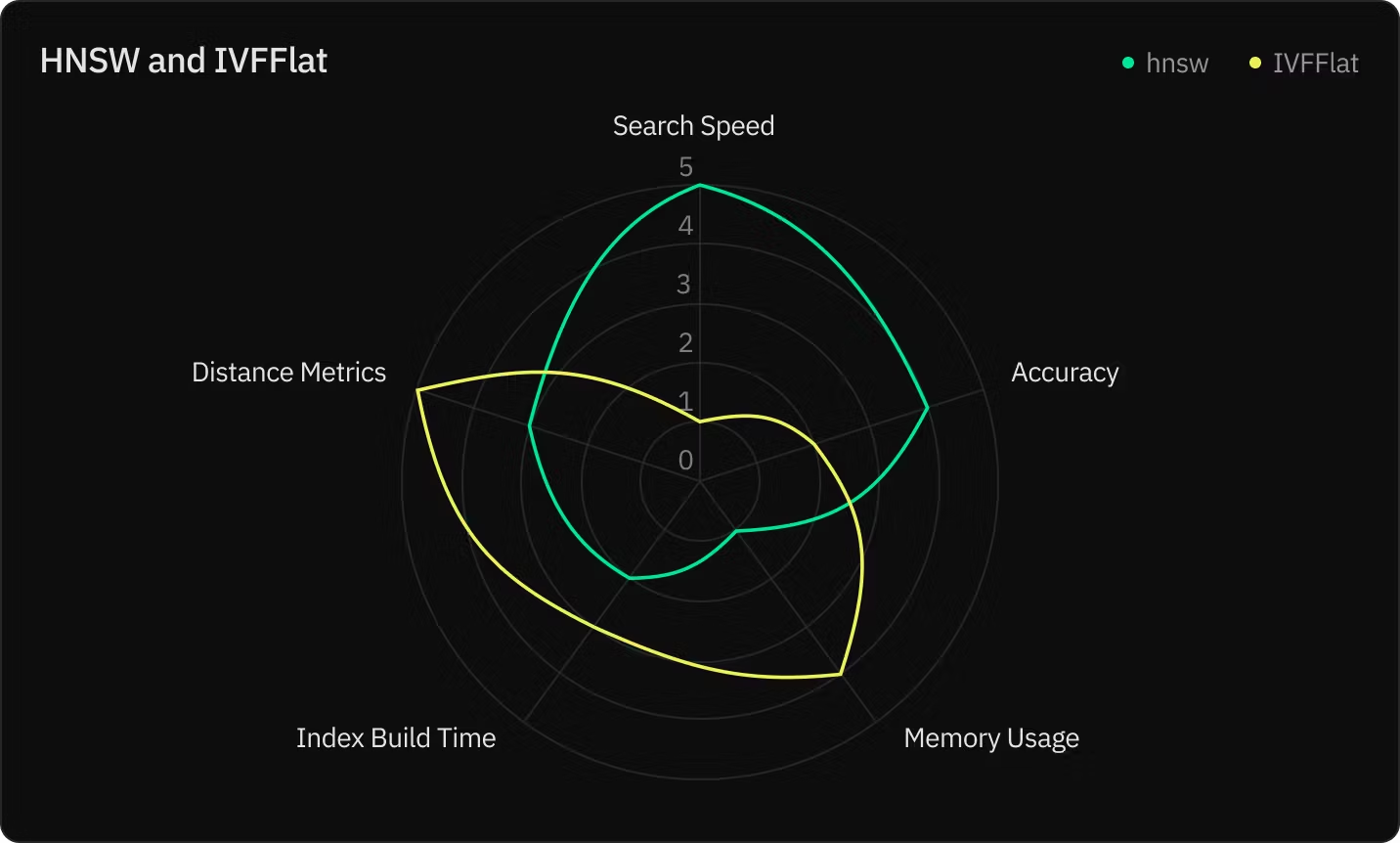
2. 构建时间: 对于百万行数据集,构建 HNSW 索引可能需要数小时。这主要是因为计算向量之间的距离需要花费时间。而这正是 pgvector 0.6.0 通过引入 并行索引构建 解决的问题。通过分配更多 CPU 和工作器,您可以将 HNSW 索引的构建速度提高 30 倍。
但是等一下!HNSW 索引支持更新,那么如果您只需要构建一次索引,为什么这个并行索引构建功能是必要的呢?
嗯,有两种情况需要创建 HNSW 索引:
当您想要更快的查询并优化向量搜索时
当你已经有 HNSW 索引,并从表中删除向量时
后者可能会导致索引搜索返回误报,从而对 LLM 响应的质量和 AI 应用程序的整体性能产生负面影响。
与以前的版本相比,pgvector 0.6.0 使用并行工作器时可将索引构建时间加快 30 倍。处理大型数据集和向量大小(例如 OpenAI 1536 维向量嵌入)时,这种改进尤其明显。
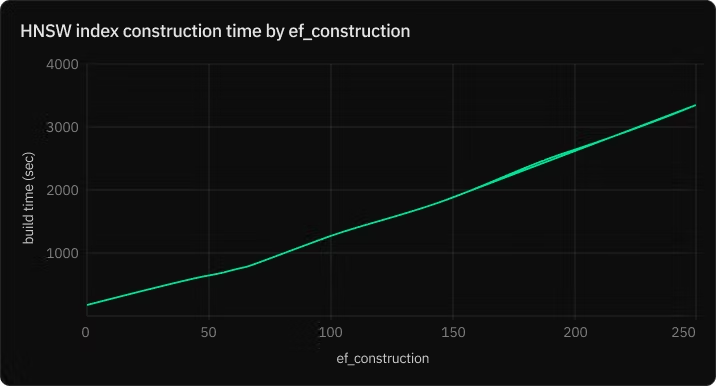
创建 HNSW 索引可能需要大量资源。原因是您需要分配足够的“maintenance_work_mem”以容纳内存中的索引。否则,hnsw 图的构建时间会更长。
NOTICE: hnsw graph no longer fits into maintenance_work_mem after 100000 tuples
DETAIL: Building will take significantly longer.
HINT: Increase maintenance_work_mem to speed up builds.
为了有效地使用并行索引构建,必须使用适当的设置配置 Postgres。需要考虑的关键参数是:
Maintenance_work_mem :此参数决定为创建或重建索引分配的内存。此参数影响这些操作的性能和效率。将其设置为较高的值(例如 8GB)可以更有效地处理索引构建过程。
SET maintenance_work_mem = '8GB';
max_parallel_maintenance_workers: 这决定了可以使用的并行工作器的数量。在 Postgres 中,max_parallel_maintenance_workers 的默认值通常设置为 2。将其设置为较大的数字可以利用更多的计算资源来更快地构建索引。
SET max_parallel_maintenance_workers = 7; -- plus leader
在 RAG 应用中,召回率与查询执行时间一样重要。召回率是 ANN 提供的正确答案的百分比。在 HNSW 索引中,“ef_search”是确定搜索时要扫描的邻居数量的参数。“ef_search”越高,召回率越高,查询执行时间越长。
Johnathan Katz 进行的测试 表明,使用并行构建对召回率的影响微乎其微,大多数变化都产生了超过 1% 的积极影响。尽管速度有了很大的提高,但召回率的这种显著稳定性凸显了 pgvector 0.6.0 并行构建过程的有效性。

pgvector 0.6.0 代表了一次重大飞跃,证明了 Postgres 在向量搜索领域的重要性。通过利用并行索引构建的强大功能,开发人员现在可以更快速、更高效地构建 HNSW 索引,从而显著减少此类任务传统上所需的时间和资源。
原文链接:https://neon.tech/blog/pgvector-30x-faster-index-build-for-your-vector-embeddings?ref=dailydev
本文由 mdnice 多平台发布