公司做铸造的招聘网站都有哪些seo网页优化公司
任务
之前写了一个相似度任务的版本:bert 相似度任务训练简单版本,faiss 寻找相似 topk-CSDN博客
相似度用的是 0,1,相当于分类任务,现在我们相似度有评分,不再是 0,1 了,分数为 0-5,数字越大代表两个句子越相似,这一次的比较完整,评估,验证集,相似度模型都有了。
数据集
链接:https://pan.baidu.com/s/1B1-PKAKNoT_JwMYJx_zT1g
提取码:er1z
原始数据好几千条,我训练数据用了部分 2500 条,验证,测试 300 左右,使用 cpu 也用了好几个小时
train.py
import torch
import os
import time
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer, BertModel, AdamW, get_cosine_schedule_with_warmup
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np# 设备选择
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = 'cpu'# 定义文本相似度数据集类
class TextSimilarityDataset(Dataset):def __init__(self, file_path, tokenizer, max_len=128):self.data = []with open(file_path, 'r', encoding='utf-8') as f:for line in f.readlines():text1, text2, similarity_score = line.strip().split('\t')inputs1 = tokenizer(text1, padding='max_length', truncation=True, max_length=max_len)inputs2 = tokenizer(text2, padding='max_length', truncation=True, max_length=max_len)self.data.append({'input_ids1': inputs1['input_ids'],'attention_mask1': inputs1['attention_mask'],'input_ids2': inputs2['input_ids'],'attention_mask2': inputs2['attention_mask'],'similarity_score': float(similarity_score),})def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]def cosine_similarity_torch(vec1, vec2, eps=1e-8):dot_product = torch.mm(vec1, vec2.t())norm1 = torch.norm(vec1, 2, dim=1, keepdim=True)norm2 = torch.norm(vec2, 2, dim=1, keepdim=True)similarity_scores = dot_product / (norm1 * norm2.t()).clamp(min=eps)return similarity_scores# 定义模型,这里我们不仅计算两段文本的[CLS] token的点积,而是整个句向量的余弦相似度
class BertSimilarityModel(torch.nn.Module):def __init__(self, pretrained_model):super(BertSimilarityModel, self).__init__()self.bert = BertModel.from_pretrained(pretrained_model)self.dropout = torch.nn.Dropout(p=0.1) # 引入Dropout层以防止过拟合def forward(self, input_ids1, attention_mask1, input_ids2, attention_mask2):embeddings1 = self.dropout(self.bert(input_ids=input_ids1, attention_mask=attention_mask1)['last_hidden_state'])embeddings2 = self.dropout(self.bert(input_ids=input_ids2, attention_mask=attention_mask2)['last_hidden_state'])# 计算两个文本向量的余弦相似度embeddings1 = torch.mean(embeddings1, dim=1)embeddings2 = torch.mean(embeddings2, dim=1)similarity_scores = cosine_similarity_torch(embeddings1, embeddings2)# 映射到[0, 5]评分范围normalized_similarities = (similarity_scores + 1) * 2.5return normalized_similarities.unsqueeze(1)# 自定义损失函数,使用Smooth L1 Loss,更适合处理回归问题
class SmoothL1Loss(torch.nn.Module):def __init__(self):super(SmoothL1Loss, self).__init__()def forward(self, predictions, targets):diff = predictions - targetsabs_diff = torch.abs(diff)quadratic = torch.where(abs_diff < 1, 0.5 * diff ** 2, abs_diff - 0.5)return torch.mean(quadratic)def train_model(model, train_loader, val_loader, epochs=3, model_save_path='../output/bert_similarity_model.pth'):model.to(device)criterion = SmoothL1Loss() # 使用自定义的Smooth L1 Lossoptimizer = AdamW(model.parameters(), lr=5e-5) # 调整初始学习率为5e-5num_training_steps = len(train_loader) * epochsscheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=0.1*num_training_steps, num_training_steps=num_training_steps) # 使用带有warmup的余弦退火学习率调度best_val_loss = float('inf')for epoch in range(epochs):model.train()for batch in train_loader:input_ids1 = batch['input_ids1'].to(device)attention_mask1 = batch['attention_mask1'].to(device)input_ids2 = batch['input_ids2'].to(device)attention_mask2 = batch['attention_mask2'].to(device)similarity_scores = batch['similarity_score'].to(device)optimizer.zero_grad()outputs = model(input_ids1, attention_mask1, input_ids2, attention_mask2)loss = criterion(outputs, similarity_scores.unsqueeze(1))loss.backward()optimizer.step()scheduler.step()# 验证阶段model.eval()with torch.no_grad():val_loss = 0total_val_samples = 0for batch in val_loader:input_ids1 = batch['input_ids1'].to(device)attention_mask1 = batch['attention_mask1'].to(device)input_ids2 = batch['input_ids2'].to(device)attention_mask2 = batch['attention_mask2'].to(device)similarity_scores = batch['similarity_score'].to(device)val_outputs = model(input_ids1, attention_mask1, input_ids2, attention_mask2)val_loss += criterion(val_outputs, similarity_scores.unsqueeze(1)).item()total_val_samples += len(similarity_scores)val_loss /= len(val_loader)print(f'Epoch {epoch + 1}, Validation Loss: {val_loss:.4f}')if val_loss < best_val_loss:best_val_loss = val_losstorch.save(model.state_dict(), model_save_path)def collate_to_tensors(batch):'''把数据处理为模型可用的数据,不同任务可能需要修改一下,'''input_ids1 = torch.tensor([example['input_ids1'] for example in batch])attention_mask1 = torch.tensor([example['attention_mask1'] for example in batch])input_ids2 = torch.tensor([example['input_ids2'] for example in batch])attention_mask2 = torch.tensor([example['attention_mask2'] for example in batch])similarity_score = torch.tensor([example['similarity_score'] for example in batch])return {'input_ids1': input_ids1, 'attention_mask1': attention_mask1, 'input_ids2': input_ids2,'attention_mask2': attention_mask2, 'similarity_score': similarity_score}# 加载数据集和预训练模型
tokenizer = BertTokenizer.from_pretrained('../bert-base-chinese')
model = BertSimilarityModel('../bert-base-chinese')# 加载数据并创建
train_data = TextSimilarityDataset('../data/STS-B/STS-B.train - 副本.data', tokenizer)
val_data = TextSimilarityDataset('../data/STS-B/STS-B.valid - 副本.data', tokenizer)
test_data = TextSimilarityDataset('../data/STS-B/STS-B.test - 副本.data', tokenizer)train_loader = DataLoader(train_data, batch_size=32, shuffle=True, collate_fn=collate_to_tensors)
val_loader = DataLoader(val_data, batch_size=32, collate_fn=collate_to_tensors)
test_loader = DataLoader(test_data, batch_size=32, collate_fn=collate_to_tensors)optimizer = AdamW(model.parameters(), lr=2e-5)# 开始训练
train_model(model, train_loader, val_loader)# 加载最佳模型进行测试
model.load_state_dict(torch.load('../output/bert_similarity_model.pth'))
test_loss = 0
total_test_samples = 0with torch.no_grad():for batch in test_loader:input_ids1 = batch['input_ids1'].to(device)attention_mask1 = batch['attention_mask1'].to(device)input_ids2 = batch['input_ids2'].to(device)attention_mask2 = batch['attention_mask2'].to(device)similarity_scores = batch['similarity_score'].to(device)test_outputs = model(input_ids1, attention_mask1, input_ids2, attention_mask2)test_loss += torch.nn.functional.mse_loss(test_outputs, similarity_scores.unsqueeze(1)).item()total_test_samples += len(similarity_scores)test_loss /= len(test_loader)
print(f'Test Loss: {test_loss:.4f}')
predit.py
这个脚本是用来看看效果的,直接传入两个文本,使用训练好的模型来计算相似度的
import torch
from transformers import BertTokenizer, BertModeldef cosine_similarity_torch(vec1, vec2, eps=1e-8):dot_product = torch.mm(vec1, vec2.t())norm1 = torch.norm(vec1, 2, dim=1, keepdim=True)norm2 = torch.norm(vec2, 2, dim=1, keepdim=True)similarity_scores = dot_product / (norm1 * norm2.t()).clamp(min=eps)return similarity_scores# 定义模型,这里我们不仅计算两段文本的[CLS] token的点积,而是整个句向量的余弦相似度
class BertSimilarityModel(torch.nn.Module):def __init__(self, pretrained_model):super(BertSimilarityModel, self).__init__()self.bert = BertModel.from_pretrained(pretrained_model)self.dropout = torch.nn.Dropout(p=0.1) # 引入Dropout层以防止过拟合def forward(self, input_ids1, attention_mask1, input_ids2, attention_mask2):'''如果是用来预测,forward 会被禁用'''pass# 加载预训练模型和分词器
tokenizer = BertTokenizer.from_pretrained('../bert-base-chinese')
model = BertSimilarityModel('../bert-base-chinese')
model.load_state_dict(torch.load('../output/bert_similarity_model.pth')) # 请确保路径正确
model.eval() # 设置模型为评估模式def calculate_similarity(text1, text2):# 对输入文本进行编码inputs1 = tokenizer(text1, padding='max_length', truncation=True, max_length=128, return_tensors='pt')inputs2 = tokenizer(text2, padding='max_length', truncation=True, max_length=128, return_tensors='pt')# 计算相似度with torch.no_grad():embeddings1 = model.bert(**inputs1.to('cpu'))['last_hidden_state'][:, 0]embeddings2 = model.bert(**inputs2.to('cpu'))['last_hidden_state'][:, 0]similarity_score = cosine_similarity_torch(embeddings1, embeddings2).item()# 映射到[0, 5]评分范围(假设训练时有此步骤)normalized_similarity = (similarity_score + 1) * 2.5return normalized_similarity# 示例
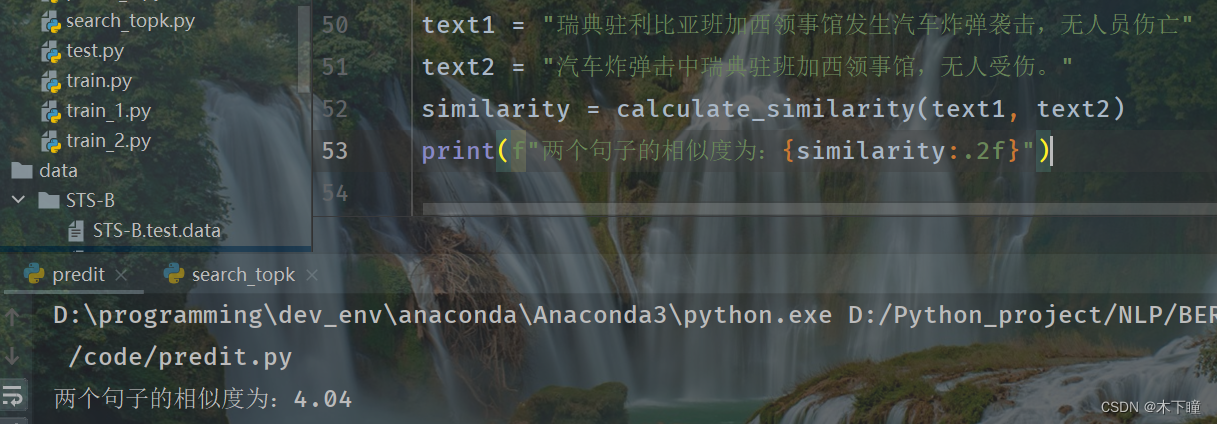
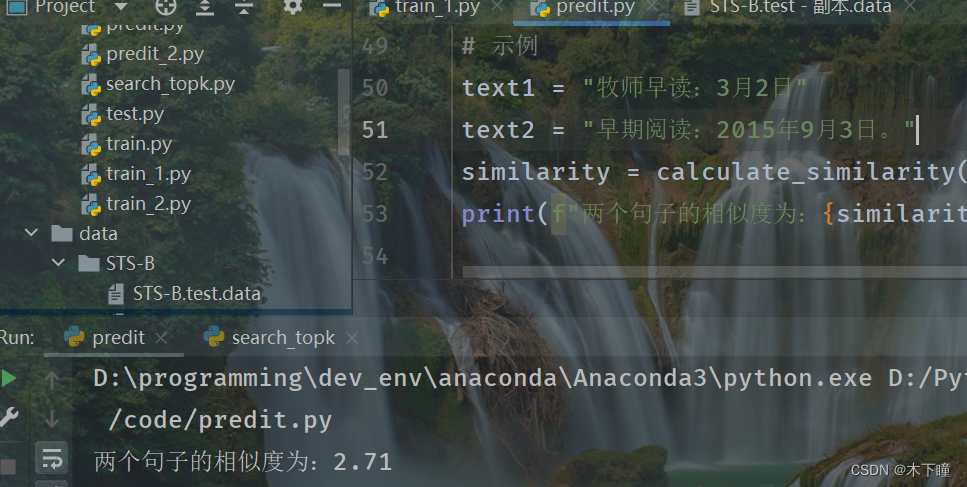
text1 = "瑞典驻利比亚班加西领事馆发生汽车炸弹袭击,无人员伤亡"
text2 = "汽车炸弹击中瑞典驻班加西领事馆,无人受伤。"
similarity = calculate_similarity(text1, text2)
print(f"两个句子的相似度为:{similarity:.2f}")