注册网站什么要求百度一下搜索网页
目录
0. 前言
1. 自调整学习率的常用方法
1.1 ExponentialLR 指数衰减方法
1.2 CosineAnnealingLR 余弦退火方法
1.3 ChainedScheduler 链式方法
2. 实例说明
3. 结果说明
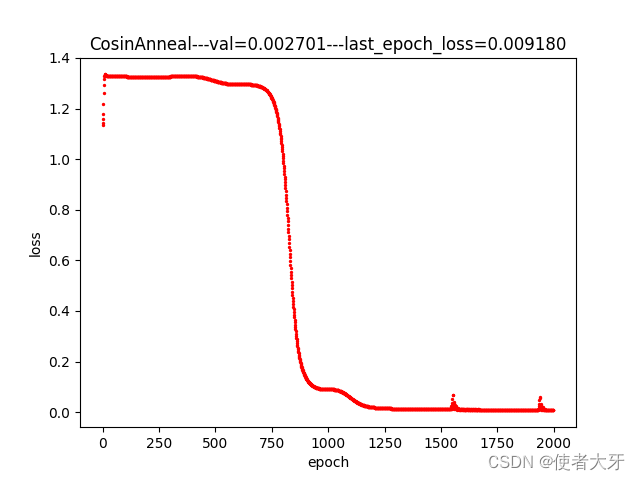
3.1 余弦退火法训练过程
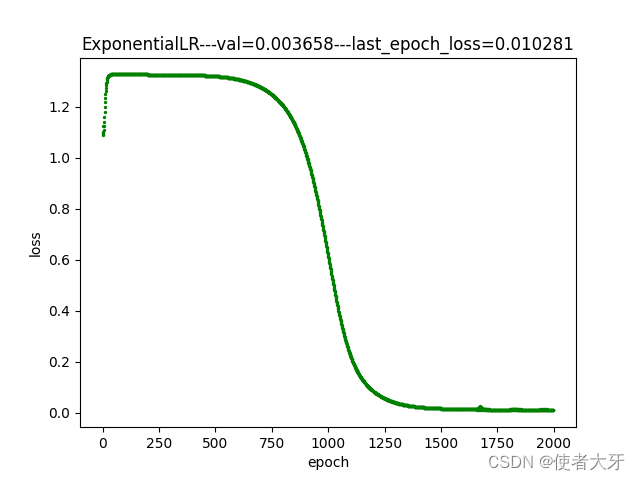
3.2 指数衰减法训练过程
3.3 恒定学习率训练过程
3.4 结果解读
4. 完整代码
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文介绍深度学习训练中经常能使用到的实用技巧——自调整学习率,并基于PyTorch框架通过实例进行使用,最后对比同样条件下以自调整学习率和固定学习率在模型训练上的表现。
在深度学习模型训练过程中,经常会出现损失值不收敛的头疼情况,令人怀疑自己设计的网络模型存在不合理或者错误之处,但是导致这种情况的真正原因往往非常简单——就是学习率的设定不合理。
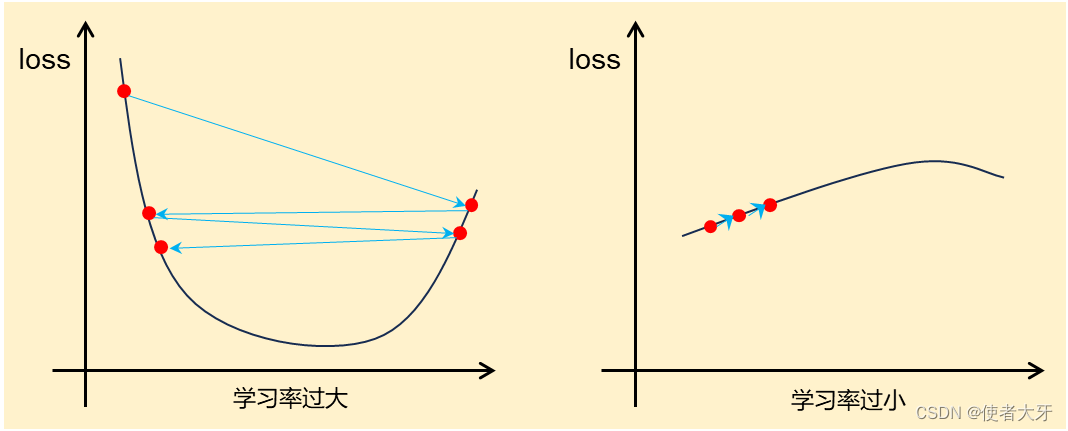
这就导致在深度学习模型训练的初期,可能需要“摸索”一个比较合适的学习率,在后期逐渐细化的过程可能还需要尝试其他的学习率,进行“分段训练”。学习率的这种“摸索”费时费力,因此自调整学习率的方法应运而生。
1. 自调整学习率的常用方法
自调整学习率是一种通用的方法,通过在训练期间动态地更新学习率以使模型更好地收敛,提高模型的精确度和稳定性。在PyTorch框架 torch.optim.lr_scheduler 中集成了大量的自调整学习率的方法:
lr_scheduler.LambdaLR
lr_scheduler.MultiplicativeLR
lr_scheduler.StepLR
lr_scheduler.MultiStepLR
lr_scheduler.ConstantLR
lr_scheduler.LinearLR
lr_scheduler.ExponentialLR
lr_scheduler.PolynomialLR
lr_scheduler.CosineAnnealingLR
lr_scheduler.ChainedScheduler
lr_scheduler.SequentialLR
lr_scheduler.ReduceLROnPlateau
lr_scheduler.CyclicLR
lr_scheduler.OneCycleLR
lr_scheduler.CosineAnnealingWarmRestarts
这里具体方法虽然很多,但是每种自动调整学习率的策略都比较简单,本文仅介绍以下两种常见的方法,其余可以查看PyTorch官网说明。
1.1 ExponentialLR 指数衰减方法
这种方法的学习率为:
这里有两个参数:
:初始学习率
:衰减指数,取值范围(0,1),一般来说取值要非常接近1(>0.95,甚至要>0.99),否则在动辄几百几千的迭代次数epoch条件下学习率很快会衰减到0
PyTorch调用代码为:
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch)- optimizer:训练该模型的优化算法
- gamma:上面的衰减指数
- last_epoch:不用理会,默认-1即可
1.2 CosineAnnealingLR 余弦退火方法
首先我要吐槽下不知道是哪个大聪明给起的这个名字,我学过《机械加工原理与工艺》,但我不明白这个算法和退火有什么关系?名字非常唬人,方法并不复杂。
这个方法就是让学习率按余弦曲线进行震荡,其震荡范围为[0, lr_initial],震荡周期为T_max:
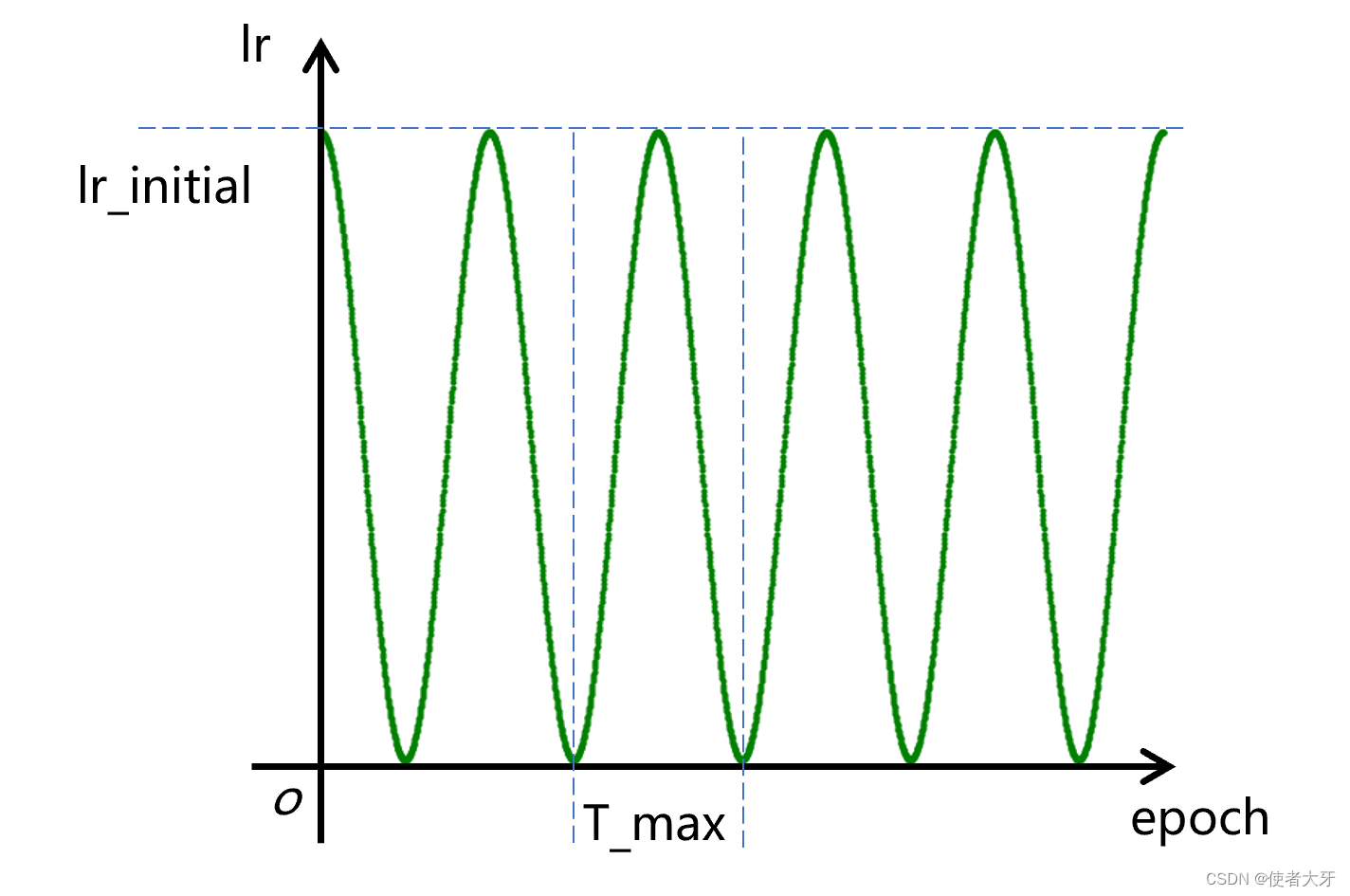
PyTorch调用代码为:
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, last_epoch)其参数同上说明不再赘述。
1.3 ChainedScheduler 链式方法
这个方法说白了就是多种自调节学习率方法进行组合使用,例如以下:
scheduler1 = ConstantLR(self.opt, factor=0.1, total_iters=2)
scheduler2 = ExponentialLR(self.opt, gamma=0.9)
scheduler = ChainedScheduler([scheduler1, scheduler2])最后再强调一下,无论使用哪种方法,在coding时别忘了每个epoch学习后加上 scheduler.step() ,这样才能更新学习率。
2. 实例说明
本文目的是验证自调节学习率的作用,选用一个简单的“平方网络”实例,即期望输出为输入值的平方。
训练输入数据x_train,输出数据y_train分别为:
x_train = torch.tensor([0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1],dtype=torch.float32).unsqueeze(-1)
y_train = torch.tensor([0.01,0.04,0.09,0.16,0.25,0.36,0.49,0.64,0.81,1],dtype=torch.float32).unsqueeze(-1)验证输入数据x_val为:
x_val = torch.tensor([0.15,0.25,0.35,0.45,0.55,0.65,0.75,0.85,0.95],dtype=torch.float32).unsqueeze(-1)网络模型使用5层全连接网络,对应这种简单问题足够用了:
class Linear(torch.nn.Module):def __init__(self):super().__init__()self.layers = torch.nn.Sequential(torch.nn.Linear(in_features=1, out_features=3),torch.nn.Sigmoid(),torch.nn.Linear(in_features=3,out_features=5),torch.nn.Sigmoid(),torch.nn.Linear(in_features=5, out_features=10),torch.nn.Sigmoid(),torch.nn.Linear(in_features=10,out_features=5),torch.nn.Sigmoid(),torch.nn.Linear(in_features=5, out_features=1),torch.nn.ReLU(),)优化器选用Adam,训练组及验证组的损失函数都选用MSE均方差。
3. 结果说明
对于本文对比的三种方法,其训练参数设定如下表:
| 学习率调整方法 | 训练参数设定 |
| 指数衰减 | 迭代次数epoch=2000,初始学习率initial_lr=0.0005,衰减指数gamma=0.99995 |
| 余弦退火 | 迭代次数epoch=2000,初始学习率initial_lr=0.001(因为学习率均值为初始值的一半,公平起见给余弦退火方法初始学习率*2),震荡周期T_max=200 |
| 恒定学习率 | 学习率lr=0.0005 |
各种方法的训练过程如下图:
3.1 余弦退火法训练过程
3.2 指数衰减法训练过程
3.3 恒定学习率训练过程
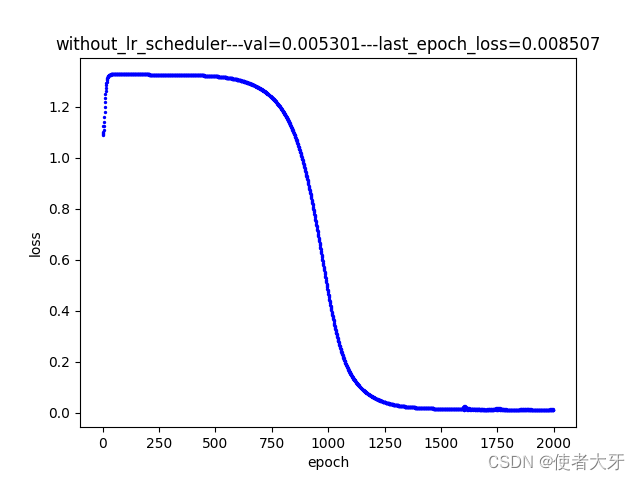
3.4 结果解读
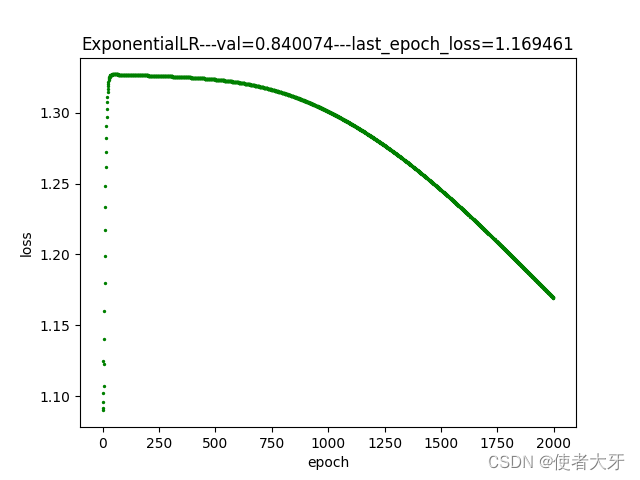
- 指数衰减方法的gamma真的要选择非常接近1才行!理由我上面也解释了,下面是gamma=0.999时的loss下降情况,可见其下降速度之慢;
- 本实例中,使用余弦退火方法训练的模型在验证组表现最好,验证组损失值val=0.0027,其次是指数衰减法(val=0.0037),最差是恒定学习率(val=0.0053),但这个结果仅限本实例中,并不是说哪种方法就比哪种方法好,在不同模型上可能要因地制宜选择合适的方法;
- 目前这些所谓的“自调节学习率”我认为仅能算是“半自动调节”,因为仍有超参数需要事前设定(例如衰减指数gamma)。而选择哪种方法最好,以及这种方法的参数如何设定呢?可能还是需要做一定的“摸索”,但是相比恒定学习率肯定会节省很多时间!
4. 完整代码
import torch
import matplotlib.pyplot as plt
from tqdm import tqdm
import argparsetorch.manual_seed(25)x_train = torch.tensor([0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1],dtype=torch.float32).unsqueeze(-1)
y_train = torch.tensor([0.01,0.04,0.09,0.16,0.25,0.36,0.49,0.64,0.81,1],dtype=torch.float32).unsqueeze(-1)
x_val = torch.tensor([0.15,0.25,0.35,0.45,0.55,0.65,0.75,0.85,0.95],dtype=torch.float32).unsqueeze(-1)class Linear(torch.nn.Module):def __init__(self):super().__init__()self.layers = torch.nn.Sequential(torch.nn.Linear(in_features=1, out_features=3),torch.nn.Sigmoid(),torch.nn.Linear(in_features=3,out_features=5),torch.nn.Sigmoid(),torch.nn.Linear(in_features=5, out_features=10),torch.nn.Sigmoid(),torch.nn.Linear(in_features=10,out_features=5),torch.nn.Sigmoid(),torch.nn.Linear(in_features=5, out_features=1),torch.nn.ReLU(),)def forward(self,x):return self.layers(x)criterion = torch.nn.MSELoss()def train_with_CosinAnneal(epoch, initial_lr, T_max):linear1 = Linear()opt = torch.optim.Adam(linear1.parameters(), lr=initial_lr)scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer=opt, T_max=T_max, last_epoch=-1)last_epoch_loss = 0for i in tqdm(range(epoch)):opt.zero_grad()total_loss = 0for j in range(len(x_train)):output = linear1(x_train[j])loss = criterion(output,y_train[j])total_loss = total_loss + loss.detach()loss.backward()opt.step()if i == epoch-1:last_epoch_loss = total_lossscheduler.step()cur_lr = scheduler.get_lr() #查看学习率变化情况# plt.scatter(i, cur_lr, s=2, c='g') plt.scatter(i, total_loss,s=2,c='r')val = 0for x in x_val:val = val + ((linear1(x) - x * x) / x * x)**2plt.title('CosinAnneal---val=%f---last_epoch_loss=%f'%(val,last_epoch_loss))plt.xlabel('epoch')plt.ylabel('loss')plt.show()def train_with_ExponentialLR(epoch, initial_lr, gamma):linear2 = Linear()opt = torch.optim.Adam(linear2.parameters(), lr=initial_lr)scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer=opt, gamma=gamma, last_epoch=-1)last_epoch_loss = 0for i in tqdm(range(epoch)):opt.zero_grad()total_loss = 0for j in range(len(x_train)):output = linear2(x_train[j])loss = criterion(output,y_train[j])total_loss = total_loss + loss.detach()loss.backward()opt.step()if i == epoch-1:last_epoch_loss = total_lossscheduler.step()cur_lr = scheduler.get_lr()# plt.scatter(i, cur_lr, s=2, c='g')plt.scatter(i, total_loss,s=2,c='g')val = 0for x in x_val:val = val + ((linear2(x) - x * x) / x * x)**2plt.title('ExponentialLR---val=%f---last_epoch_loss=%f'%(val,last_epoch_loss))plt.xlabel('epoch')plt.ylabel('loss')plt.show()def train_without_lr_scheduler(epoch, initial_lr):linear3 = Linear()opt = torch.optim.Adam(linear3.parameters(), lr=initial_lr)last_epoch_loss = 0for i in tqdm(range(epoch)):opt.zero_grad()total_loss = 0for j in range(len(x_train)):output = linear3(x_train[j])loss = criterion(output, y_train[j])total_loss = total_loss + loss.detach()loss.backward()opt.step()if i == epoch-1:last_epoch_loss = total_lossplt.scatter(i, total_loss, s=2, c='b')val = 0for x in x_val:val = val + ((linear3(x) - x * x) / x * x)**2plt.title('without_lr_scheduler---val=%f---last_epoch_loss=%f'%(val,last_epoch_loss))plt.xlabel('epoch')plt.ylabel('loss')plt.show()if __name__ == '__main__' :epoch = 2000initial_lr = 0.0005gamma = 0.99995T_max = 200Cosine_Anneal_args = [epoch,initial_lr*2,T_max]train_with_CosinAnneal(*Cosine_Anneal_args)# ExponentialLR_args = [epoch, initial_lr, gamma]# train_with_ExponentialLR(*ExponentialLR_args)## without_scheduler_args = [epoch, initial_lr]# train_without_lr_scheduler(*without_scheduler_args)