服务器在香港的网站网站内容编辑
提示:GPU-manager安装为主部分内容做了升级开箱即用,有用请点收藏❤抱拳
文章目录
- 前言
- 一、约束条件
- 二、使用步骤
- 1.下载镜像
- 1.1 查看当前虚拟机的驱动类型:
- 2.部署gpu-manager
- 3.部署gpu-admission
- 4.修改kube-scheduler.yaml
- 4.1 新建/etc/kubernetes/scheduler-policy-config.json
- 4.2 新建/etc/kubernetes/scheduler-extender.yaml
- 4.3 修改/etc/kubernetes/manifests/kube-scheduler.yaml
- 4.1 结果查看
- 测试
- 总结
前言
本文只做开箱即用部分,想了解GPUManager虚拟化方案技术层面请直接点击:GPUmanager虚拟化方案
一、约束条件
1、虚拟机需要完成直通式绑定,也就是物理GPU与虚拟机绑定,我做的是hyper-v的虚拟机绑定参照上一篇文章
2、对于k8s要求1.10版本以上
3、GPU-Manager 要求集群内包含 GPU 机型节点
4、每张 GPU 卡一共有100个单位的资源,仅支持0 - 1的小数卡,以及1的倍数的整数卡设置。显存资源是以256MiB为最小的一个单位的分配显存
我的版本:k8s-1.20
二、使用步骤
1.下载镜像
镜像地址:https://hub.docker.com/r/tkestack/gpu-manager/tags
manager:docker pull tkestack/gpu-manager:v1.1.5
https://hub.docker.com/r/tkestack/gpu-quota-admission/tags
admission:docker pull tkestack/gpu-quota-admission:v1.0.0
1.1 查看当前虚拟机的驱动类型:
docker info

2.部署gpu-manager
拥有GPU节点打标签:
kubectl label node XX nvidia-device-enable=enable
如果docker驱动是systemd 需要在yaml指定,因为GPUmanager默认cgroupfs
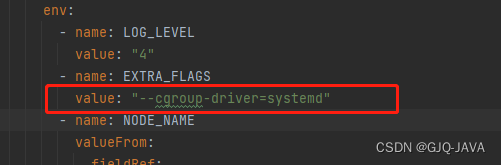
创建yaml内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:name: gpu-managernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: gpu-manager-role
subjects:- kind: ServiceAccountname: gpu-managernamespace: kube-system
roleRef:kind: ClusterRolename: cluster-adminapiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: gpu-manager-daemonsetnamespace: kube-system
spec:updateStrategy:type: RollingUpdateselector:matchLabels:name: gpu-manager-dstemplate:metadata:# This annotation is deprecated. Kept here for backward compatibility# See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/annotations:scheduler.alpha.kubernetes.io/critical-pod: ""labels:name: gpu-manager-dsspec:serviceAccount: gpu-managertolerations:# This toleration is deprecated. Kept here for backward compatibility# See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/- key: CriticalAddonsOnlyoperator: Exists- key: tencent.com/vcuda-coreoperator: Existseffect: NoSchedule# Mark this pod as a critical add-on; when enabled, the critical add-on# scheduler reserves resources for critical add-on pods so that they can# be rescheduled after a failure.# See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/priorityClassName: "system-node-critical"# only run node has gpu devicenodeSelector:nvidia-device-enable: enablehostPID: truecontainers:- image: tkestack/gpu-manager:v1.1.5imagePullPolicy: IfNotPresentname: gpu-managersecurityContext:privileged: trueports:- containerPort: 5678volumeMounts:- name: device-pluginmountPath: /var/lib/kubelet/device-plugins- name: vdrivermountPath: /etc/gpu-manager/vdriver- name: vmdatamountPath: /etc/gpu-manager/vm- name: logmountPath: /var/log/gpu-manager- name: checkpointmountPath: /etc/gpu-manager/checkpoint- name: run-dirmountPath: /var/run- name: cgroupmountPath: /sys/fs/cgroupreadOnly: true- name: usr-directorymountPath: /usr/local/hostreadOnly: true- name: kube-rootmountPath: /root/.kubereadOnly: trueenv:- name: LOG_LEVELvalue: "4"- name: EXTRA_FLAGSvalue: "--cgroup-driver=systemd"- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeNamevolumes:- name: device-pluginhostPath:type: Directorypath: /var/lib/kubelet/device-plugins- name: vmdatahostPath:type: DirectoryOrCreatepath: /etc/gpu-manager/vm- name: vdriverhostPath:type: DirectoryOrCreatepath: /etc/gpu-manager/vdriver- name: loghostPath:type: DirectoryOrCreatepath: /etc/gpu-manager/log- name: checkpointhostPath:type: DirectoryOrCreatepath: /etc/gpu-manager/checkpoint# We have to mount the whole /var/run directory into container, because of bind mount docker.sock# inode change after host docker is restarted- name: run-dirhostPath:type: Directorypath: /var/run- name: cgrouphostPath:type: Directorypath: /sys/fs/cgroup# We have to mount /usr directory instead of specified library path, because of non-existing# problem for different distro- name: usr-directoryhostPath:type: Directorypath: /usr- name: kube-roothostPath:type: Directorypath: /root/.kube执行yaml文件:
kubectl apply -f gpu-manager.yaml
kubectl get pod -A|grep gpu 查询结果
3.部署gpu-admission
创建yaml内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:name: gpu-admissionnamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: gpu-admission-as-kube-scheduler
subjects:- kind: ServiceAccountname: gpu-admissionnamespace: kube-system
roleRef:kind: ClusterRolename: system:kube-schedulerapiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: gpu-admission-as-volume-scheduler
subjects:- kind: ServiceAccountname: gpu-admissionnamespace: kube-system
roleRef:kind: ClusterRolename: system:volume-schedulerapiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: gpu-admission-as-daemon-set-controller
subjects:- kind: ServiceAccountname: gpu-admissionnamespace: kube-system
roleRef:kind: ClusterRolename: system:controller:daemon-set-controllerapiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:labels:component: schedulertier: control-planeapp: gpu-admissionname: gpu-admissionnamespace: kube-system
spec:selector:matchLabels:component: schedulertier: control-planereplicas: 1template:metadata:labels:component: schedulertier: control-planeversion: secondspec:serviceAccountName: gpu-admissioncontainers:- image: thomassong/gpu-admission:47d56ae9name: gpu-admissionenv:- name: LOG_LEVELvalue: "4"ports:- containerPort: 3456dnsPolicy: ClusterFirstWithHostNethostNetwork: truepriority: 2000000000priorityClassName: system-cluster-critical
---
apiVersion: v1
kind: Service
metadata:name: gpu-admissionnamespace: kube-system
spec:ports:- port: 3456protocol: TCPtargetPort: 3456selector:app: gpu-admissiontype: ClusterIP
执行yaml文件:
kubectl create -f gpu-admission.yaml
kubectl get pod -A|grep gpu 查询结果
4.修改kube-scheduler.yaml
4.1 新建/etc/kubernetes/scheduler-policy-config.json
创建内容:
vim /etc/kubernetes/scheduler-policy-config.json
复制如下内容:
{"kind": "Policy","apiVersion": "v1","predicates": [{"name": "PodFitsHostPorts"},{"name": "PodFitsResources"},{"name": "NoDiskConflict"},{"name": "MatchNodeSelector"},{"name": "HostName"}],"priorities": [{"name": "BalancedResourceAllocation","weight": 1},{"name": "ServiceSpreadingPriority","weight": 1}],"extenders": [{"urlPrefix": "http://gpu-admission.kube-system:3456/scheduler","apiVersion": "v1beta1","filterVerb": "predicates","enableHttps": false,"nodeCacheCapable": false}],"hardPodAffinitySymmetricWeight": 10,"alwaysCheckAllPredicates": false
}4.2 新建/etc/kubernetes/scheduler-extender.yaml
创建内容:
vim /etc/kubernetes/scheduler-extender.yaml
复制如下内容:
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
clientConnection:kubeconfig: "/etc/kubernetes/scheduler.conf"
algorithmSource:policy:file:path: "/etc/kubernetes/scheduler-policy-config.json"4.3 修改/etc/kubernetes/manifests/kube-scheduler.yaml
修改内容:
vim /etc/kubernetes/manifests/kube-scheduler.yaml
复制如下内容:
apiVersion: v1
kind: Pod
metadata:creationTimestamp: nulllabels:component: kube-schedulertier: control-planename: kube-schedulernamespace: kube-system
spec:containers:- command:- kube-scheduler- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf- --bind-address=0.0.0.0- --feature-gates=TTLAfterFinished=true,ExpandCSIVolumes=true,CSIStorageCapacity=true,RotateKubeletServerCertificate=true- --kubeconfig=/etc/kubernetes/scheduler.conf- --leader-elect=true- --port=0- --config=/etc/kubernetes/scheduler-extender.yamlimage: registry.cn-beijing.aliyuncs.com/kubesphereio/kube-scheduler:v1.22.10imagePullPolicy: IfNotPresentlivenessProbe:failureThreshold: 8httpGet:path: /healthzport: 10259scheme: HTTPSinitialDelaySeconds: 10periodSeconds: 10timeoutSeconds: 15name: kube-schedulerresources:requests:cpu: 100mstartupProbe:failureThreshold: 24httpGet:path: /healthzport: 10259scheme: HTTPSinitialDelaySeconds: 10periodSeconds: 10timeoutSeconds: 15volumeMounts:- mountPath: /etc/kubernetes/scheduler.confname: kubeconfigreadOnly: true- mountPath: /etc/localtimename: localtimereadOnly: true- mountPath: /etc/kubernetes/scheduler-extender.yamlname: extenderreadOnly: true- mountPath: /etc/kubernetes/scheduler-policy-config.jsonname: extender-policyreadOnly: truehostNetwork: truepriorityClassName: system-node-criticalsecurityContext:seccompProfile:type: RuntimeDefaultvolumes:- hostPath:path: /etc/kubernetes/scheduler.conftype: FileOrCreatename: kubeconfig- hostPath:path: /etc/localtimetype: Filename: localtime- hostPath:path: /etc/kubernetes/scheduler-extender.yamltype: FileOrCreatename: extender- hostPath:path: /etc/kubernetes/scheduler-policy-config.jsontype: FileOrCreatename: extender-policy
status: {}
修改内容入下:
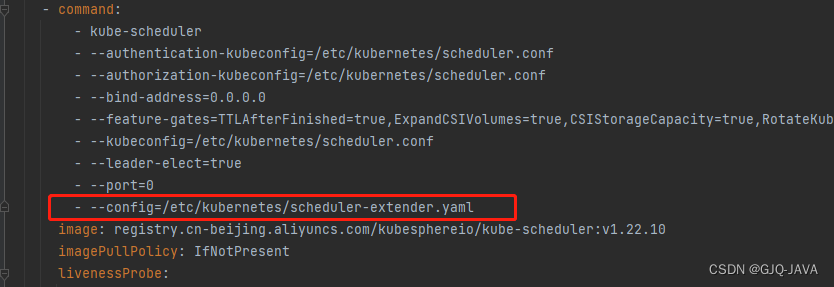
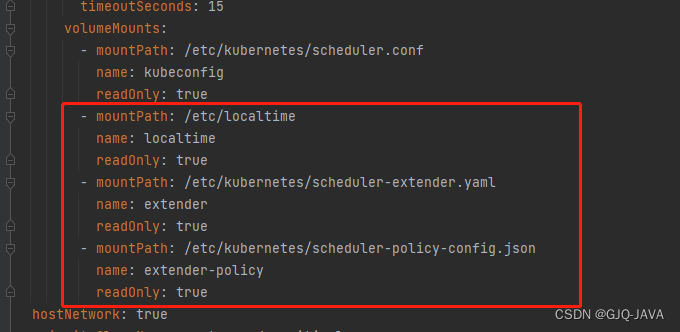
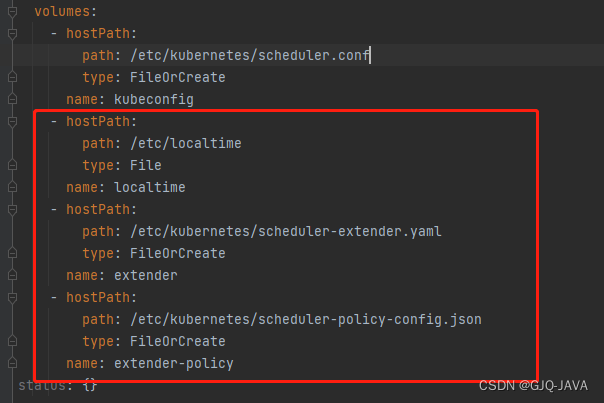
修改完成k8s自动重启,如果没有重启执行 kubectl delete pod -n [podname]
4.1 结果查看
执行命令:
kubectl describe node master[节点名称]
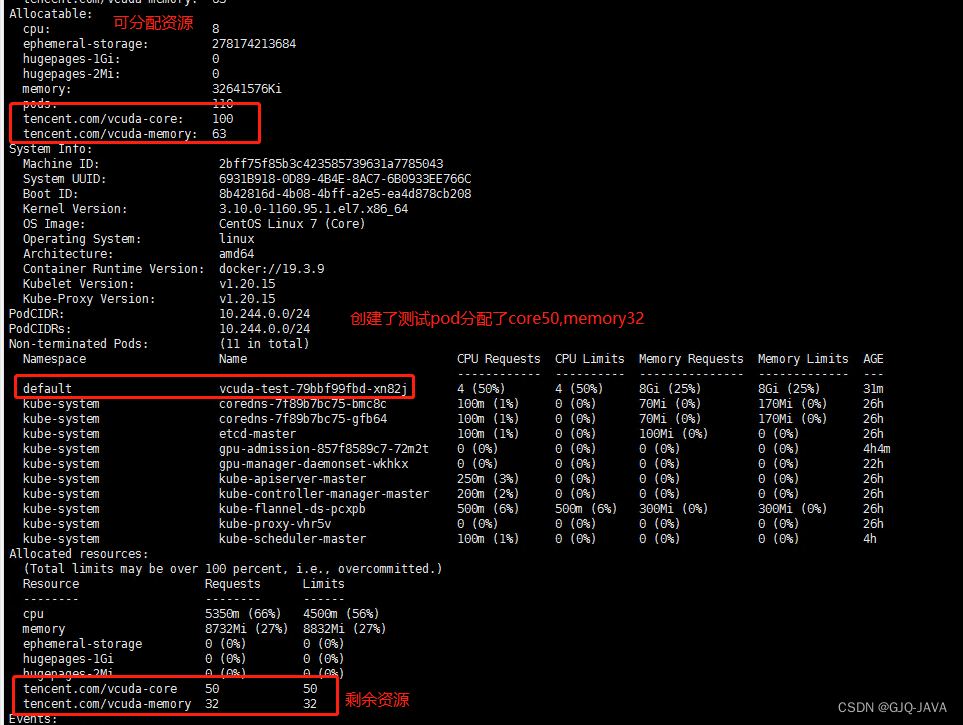
测试
镜像下载:docker pull gaozhenhai/tensorflow-gputest:0.2
创建yaml内容: vim vcuda-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:k8s-app: vcuda-testqcloud-app: vcuda-testname: vcuda-testnamespace: default
spec:replicas: 1selector:matchLabels:k8s-app: vcuda-testtemplate:metadata:labels:k8s-app: vcuda-testqcloud-app: vcuda-testspec:containers:- command:- sleep- 360000senv:- name: PATHvalue: /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/binimage: gaozhenhai/tensorflow-gputest:0.2imagePullPolicy: IfNotPresentname: tensorflow-testresources:limits:cpu: "4"memory: 8Gitencent.com/vcuda-core: "50"tencent.com/vcuda-memory: "32"requests:cpu: "4"memory: 8Gitencent.com/vcuda-core: "50"tencent.com/vcuda-memory: "32"
启动yaml:kubectl apply -f vcuda-test.yaml
进入容器:
kubectl exec -it `kubectl get pods -o name | cut -d '/' -f2` -- bash
执行测试命令:
cd /data/tensorflow/cifar10 && time python cifar10_train.py
查看结果:
执行命令:nvidia-smi pmon -s u -d 1、命令查看GPU资源使用情况
总结
到此vgpu容器层虚拟化全部完成