网站备案ip地址段上海网站建设方案
聚类问题是无监督学习,算法的思想是“物以类聚,人以群分”。聚类算法感知样本间的相似度,进行类别归纳,对新的输入进行输出预测,输出变量取有限个离散值
K-means
又称K-均值或K-平均聚类算法。算法思想就是首先随机确定K个中心点作为聚类中心,然后把每个数据点分配给最邻近的中心点,分配完成后形成K个聚类,计算各个聚类的平均中心点,将其作为该聚类新的类中心点,然后重复迭代上述步骤直到分配过程不再产生变化
K-Means的主要优点:
- 原理比较简单,实现也容易,收敛速度快
- 聚类效果较优
- 算法的可解释度比较强
- 主要需要调参的参数仅仅是簇数K
K-Means的缺点
- K值的选取不好把握
- 不平衡数据集的聚类效果不佳
- 采用迭代方法,得到的结果只是局部最优
- 对噪音和异常点比较的敏感
高斯混合模型
指的是多个高斯分布函数的线性组合,是一种广泛使用的聚类算法,该方法使用了高斯分布作为参数模型
- 单高斯模型:高斯分布,有时又称为正态分布
- 高斯混合模型:混合模型是一个可以用来表示在总体分布中含有K个子分布的概率模型,换句话说,混合模型表示了观测数据在总体中的概率分布,他是一个由k个子分布组成的混合分布
- 混合高斯和K-means很相似,相似点在于两者的分类受初始值影响;两者可能限于局部最优解;两者的类别的个数都要靠采择。混合高斯计算复杂度高于k-means
- k-means属于硬聚类,要么属于这类,要么属于那类;而GMM属于混合式软聚类,一个样本70%属于A,30%属于B
密度聚类:
密度聚类算法假设聚类结构能通过样本分布的密度程度确定,算法从样本密度的角度来考察样本之间的可连接性,并给予可连接样本不断扩展聚类簇已获得最终的聚类结构
层次聚类
层次聚类算法试图在不同层次对数据进行划分,从而形成树形的聚类结构。数据集的划分可采用“自底向上”的聚合策略,也可采用“自顶向下”的分拆策略
谱聚类
它是一种基于图论的聚类方法,将带权无向图划分为两个或两个以上的最有子图,使子图内部尽量相似,而子图键距离尽量距离较远,以达到常见的聚类的目的
#分割线
数据建模-聚类分析
聚类分析将研究对象进行分类,其目的是把相似的对象归一个类,使得类内的对象同质性最大化,类间的对象异质性最大化。
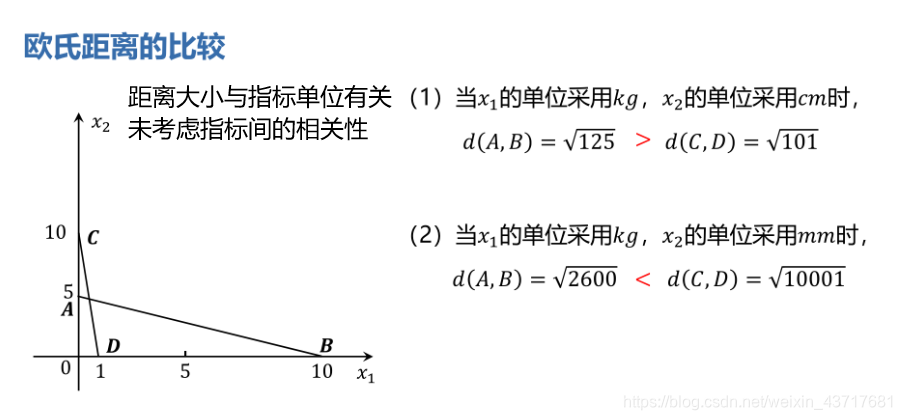
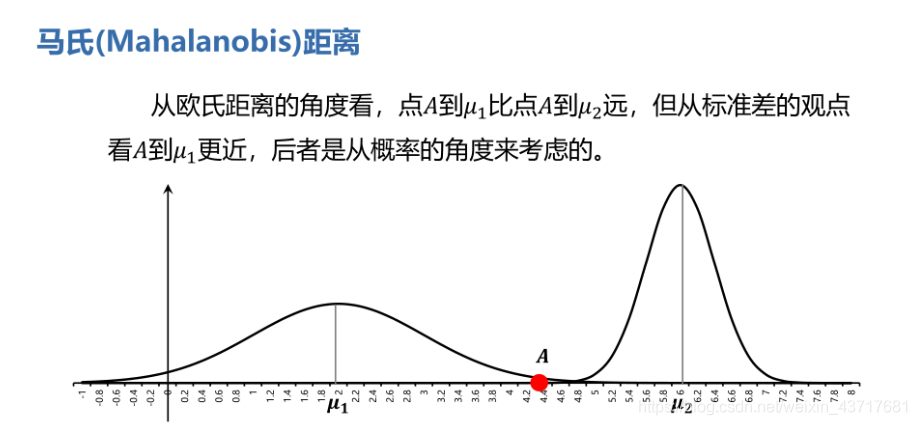
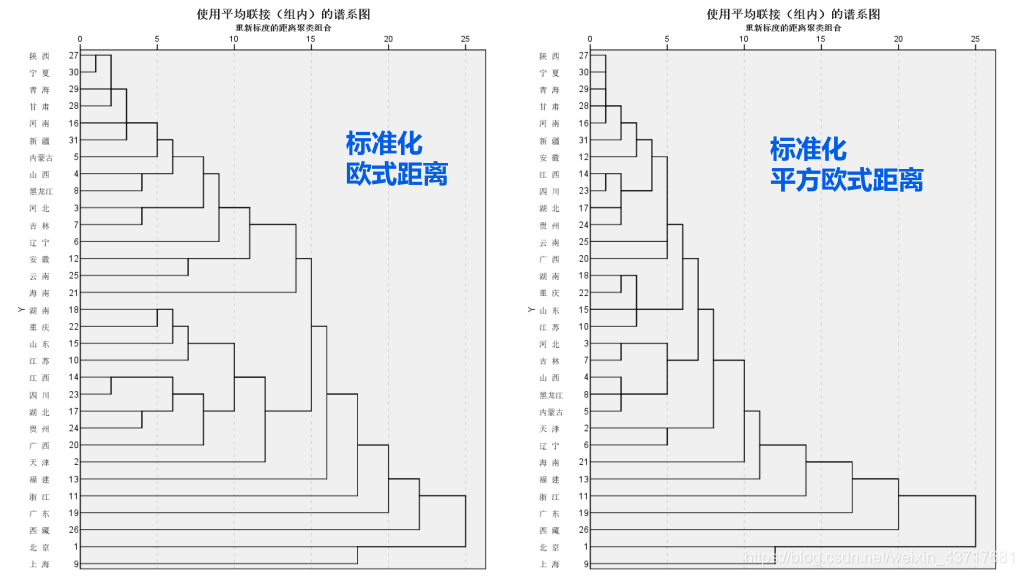
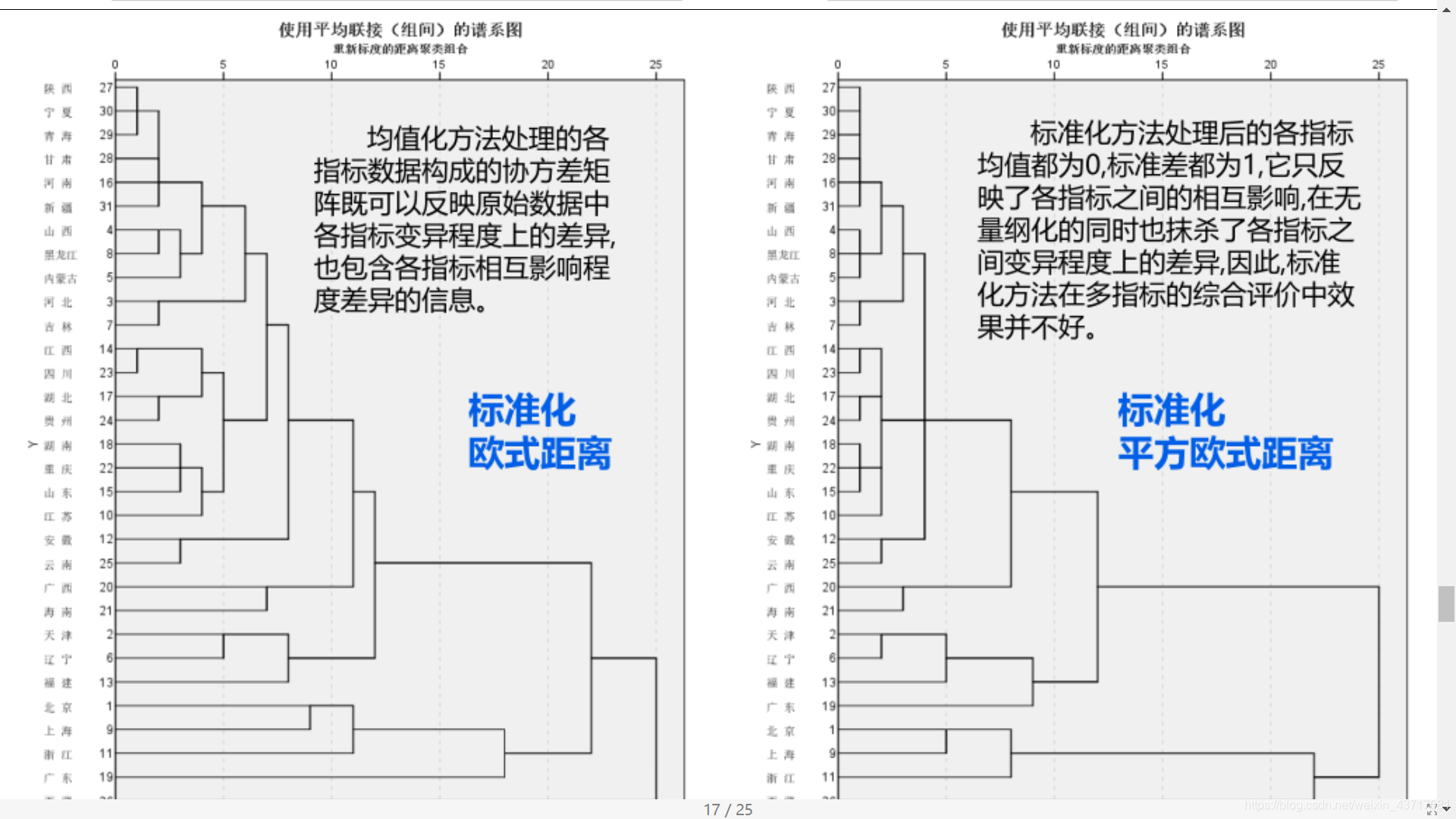
对样品进行分类时,相似或相近常用某种距离来刻画,称为Q型聚类分析;对指标(变量)进行分类时,常根据相关系数或某种关联性来度量相似或相近,称为R型聚类分析。
聚类分析、判别分析和回归分析一起称为多元分析的三大方法。

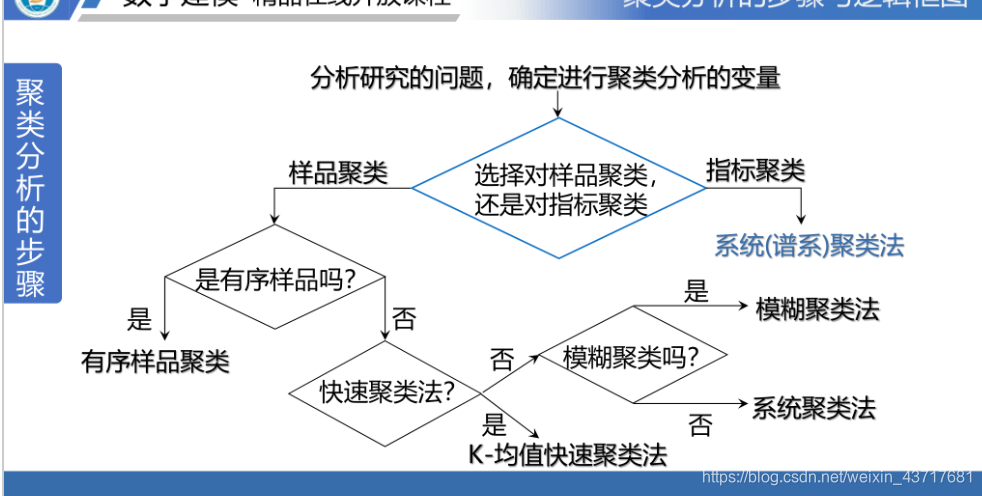
常用聚类方法:
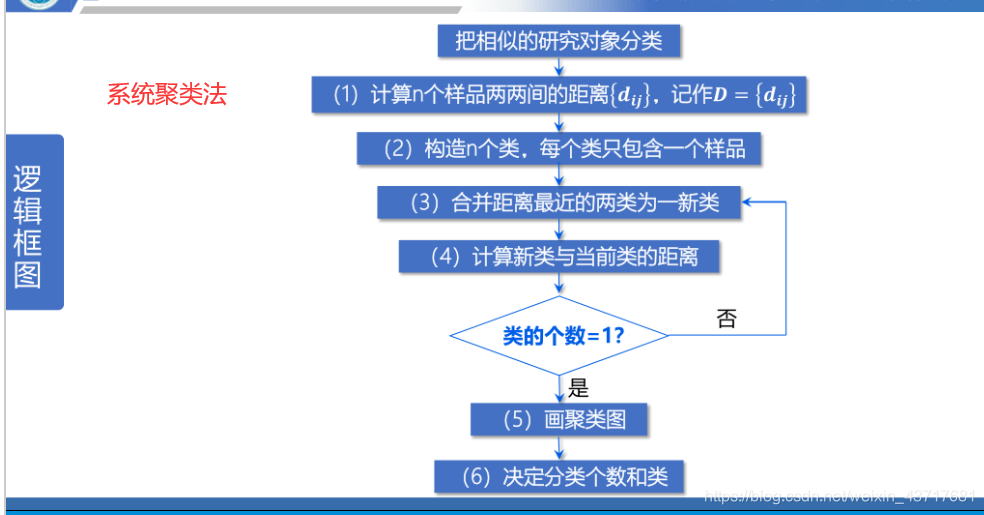
系统(谱系)聚类法:n个样品看成n个类,依次将最相近的两类合并,最后并为一个类。
有序样品聚类法:n个样品按某种原因(如时间、程度等)排成次序,必定是次序相邻的样品才可以聚为一类。
K-均值(快速)聚类法:是一种非谱系聚类法,它把n个样品聚为k(k<n)个类,其中k可以预先给定或在聚类过程中产生。
模糊聚类法:是将模糊数学的思想观点用到聚类分析上,多用于对定性指标(变量)得分类