媒体网站开发优化推荐
LlamaIndex 是一个数据框架,供 LLM 应用程序摄取、构建和访问私有或特定领域的数据。
LlamaIndex 是开源的,可用于构建各种应用程序。 在 GitHub 上查看该项目。

安装
在 Docker 上设置 Elasticsearch
使用以下 docker 命令启动单节点 Elasticsearch 实例。我们可以参考之前的文章 “Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发”。我选择不使用安全配置。直接使用 docker compose 来启动 Elasticsearch 及 Kibana:
.env
$ pwd
/Users/liuxg/data/docker8
$ ls -al
total 16
drwxr-xr-x 4 liuxg staff 128 Jan 16 13:00 .
drwxr-xr-x 193 liuxg staff 6176 Jan 12 08:31 ..
-rw-r--r-- 1 liuxg staff 21 Jan 16 13:00 .env
-rw-r--r-- 1 liuxg staff 733 Mar 14 2023 docker-compose.yml
$ cat .env
STACK_VERSION=8.11.3docker-compose.yml
version: "3.9"
services:elasticsearch:image: elasticsearch:${STACK_VERSION}container_name: elasticsearchenvironment:- discovery.type=single-node- ES_JAVA_OPTS=-Xms1g -Xmx1g- xpack.security.enabled=falsevolumes:- type: volumesource: es_datatarget: /usr/share/elasticsearch/dataports:- target: 9200published: 9200networks:- elastickibana:image: kibana:${STACK_VERSION}container_name: kibanaports:- target: 5601published: 5601depends_on:- elasticsearchnetworks:- elastic volumes:es_data:driver: localnetworks:elastic:name: elasticdriver: bridge我们使用如下的命令来启动:
docker-compose up
这样我们就完成了 Elasticsearch 及 Kibana 的安装了。我们的 Elasticsearch 及 Kibana 都没有安全的设置。这个在生产环境中不被推荐使用。
应用设计 - 组装管道
我们将使用 Jupyter notebook 来进行设计。我们在命令行中打入:
jupyter notebook安装依赖
我们使用如下的命令来安装 Python 的依赖包:
pip3 install llama-index openai elasticsearch load_dotenv我们接下来在当前的工作目录中创建一个叫做 .env 的文件:
.env
OPENAI_API_KEY="YourOpenAIKey"请在 .env 中创建如上所示的变量。你需要把自己的 openai key 写入到上面的文件里。
加载模块及读取环境变量
import logging
import sys
import os
from dotenv import load_dotenvload_dotenv()logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')import openai连接到 Elasticsearch
ElasticsearchStore 类用于连接到 Elasticsearch 实例。 它需要以下参数:
- index_name:Elasticsearch 索引的名称。 必需的。
- es_client:可选。 预先存在的 Elasticsearch 客户端。
- es_url:可选。Elasticsearch 网址。
- es_cloud_id:可选。 Elasticsearch 云 ID。
- es_api_key:可选。 Elasticsearch API 密钥。
- es_user:可选。 Elasticsearch 用户名。
- es_password:可选。 弹性搜索密码。
- text_field:可选。 存储文本的 Elasticsearch 字段的名称。
- vector_field:可选。 存储 Elasticsearch 字段的名称嵌入。
- batch_size:可选。 批量索引的批量大小。 默认为 200。
- distance_strategy:可选。 用于相似性搜索的距离策略。默认为 “COSINE”。
针对,我们的情况,我们可以使用如下的示例方法来进行本地连接:
from llama_index.vector_stores import ElasticsearchStorees = ElasticsearchStore(index_name="my_index",es_url="http://localhost:9200",
)我们将在下面的代码中使用上述的方法来连接 Elasticsearch。
加载文档,使用 Elasticsearch 构建 VectorStoreIndex
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores import ElasticsearchStore!mkdir -p 'data/paul_graham/'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham/paul_graham_essay.txt'
运行完上面的命令后,我们可以在当前的目录下查看:
$ pwd
/Users/liuxg/python/elser
$ ls data/paul_graham/
paul_graham_essay.txt我们可以看到一个叫做 pau_graham_essay.txt 的文件。它的内容如下:
What I Worked OnFebruary 2021Before college the two main things I worked on, outside of school, were writing and programming. I didn't write essays. I wrote what beginning writers were supposed to write then, and probably still are: short stories. My stories were awful. They had hardly any plot, just characters with strong feelings, which I imagined made them deep.The first programs I tried writing were on the IBM 1401 that our school district used for what was then called "data processing." This was in 9th grade, so I was 13 or 14. The school district's 1401 happened to be in the basement of our junior high school, and my friend Rich Draves and I got permission to use it. It was like a mini Bond villain's lair down there, with all these alien-looking machines — CPU, disk drives, printer, card reader — sitting up on a raised floor under bright fluorescent lights....The language we used was an early version of Fortran. You had to type programs on punch cards, then stack them in the card reader and press a button to load the program into memory and run it. The result would ordinarily be to print something on the spectacularly loud printer.I was puzzled by the 1401. I couldn't figure out what to do with it. And in retrospect there's not much I could have done with it. The only form of input to programs was data stored on punched cards, and I didn't have any data stored on punched cards. The only other option was to do things that didn't rely on any input, like calculate approximations of pi, but I didn't know enough math to do anything interesting of that type. So I'm not surprised I can't remember any programs I wrote, because they can't have done much. My clearest memory is of the moment I learned it was possible for programs not to terminate, when one of mine didn't. On a machine without time-sharing, this was a social as well as a technical error, as the data center manager's expression made clear.
...Toward the end of the summer I got a big surprise: a letter from the Accademia, which had been delayed because they'd sent it to Cambridge England instead of Cambridge Massachusetts, inviting me to take the entrance exam in Florence that fall. This was now only weeks away. My nice landlady let me leave my stuff in her attic. I had some money saved from consulting work I'd done in grad school; there was probably enough to last a year if I lived cheaply. Now all I had to do was learn Italian.
...documents = SimpleDirectoryReader("./data/paul_graham/").load_data()from llama_index.storage.storage_context import StorageContextvector_store = ElasticsearchStore(es_url="http://localhost:9200",# Or with Elastic Cloud# es_cloud_id="my_cloud_id",# es_user="elastic",# es_password="my_password",index_name="paul_graham",
)storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context
)
基本查询
我们将向查询引擎询问有关我们刚刚索引的数据的问题。
# set Logging to DEBUG for more detailed outputs
query_engine = index.as_query_engine()
response = query_engine.query("what were his investments in Y Combinator?")
print(response)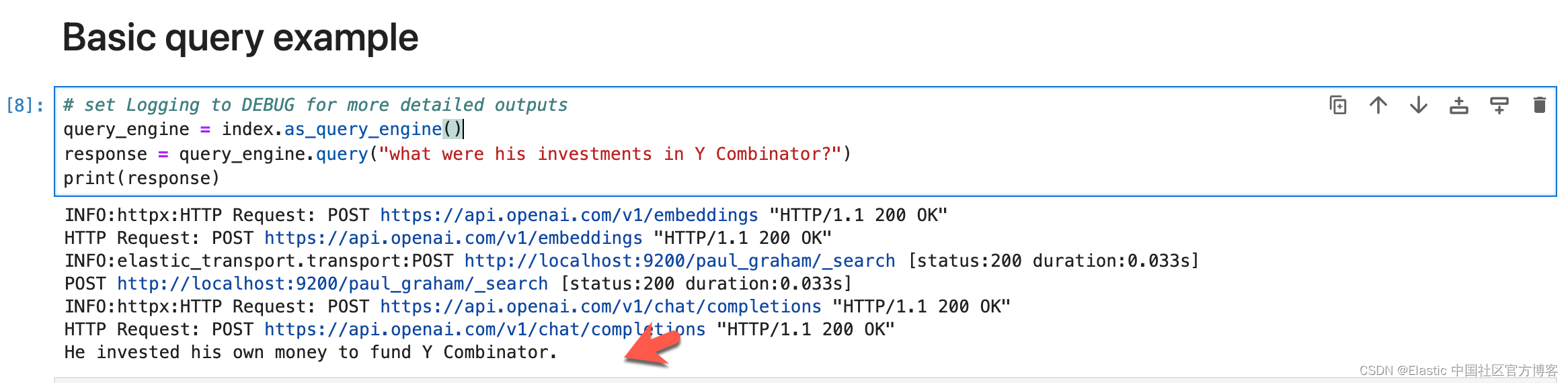
元数据过滤器
在这里,我们将使用元数据索引一些文档,以便我们可以将过滤器应用于查询引擎。
from llama_index.schema import TextNodenodes = [TextNode(text="The Shawshank Redemption",metadata={"author": "Stephen King","theme": "Friendship",},),TextNode(text="The Godfather",metadata={"director": "Francis Ford Coppola","theme": "Mafia",},),TextNode(text="Beautiful weather",metadata={"director": "Mark shuttle","theme": "Mafia",},), TextNode(text="Inception",metadata={"director": "Christopher Nolan",},),
]# initialize the vector store
vector_store_metadata_example = ElasticsearchStore(index_name="movies_metadata_example",es_url="http://localhost:9200",
)
storage_context = StorageContext.from_defaults(vector_store=vector_store_metadata_example
)
index1 = VectorStoreIndex(nodes, storage_context=storage_context)# Metadata filter
from llama_index.vector_stores.types import ExactMatchFilter, MetadataFiltersfilters = MetadataFilters(filters=[ExactMatchFilter(key="theme", value="Mafia")]
)retriever = index1.as_retriever(filters=filters)retriever.retrieve("weather is so beautiful") 在上面,我们搜索的是 “weather is so beautiful”,从而在两个 theme 为 Mafia 的 Texnode 里,Mark shuttle 位列第一。这个是因为 “weather is so beautiful” 更和 “Beautiful weather” 更为贴近。 如果我们使用如下的查询:
在上面,我们搜索的是 “weather is so beautiful”,从而在两个 theme 为 Mafia 的 Texnode 里,Mark shuttle 位列第一。这个是因为 “weather is so beautiful” 更和 “Beautiful weather” 更为贴近。 如果我们使用如下的查询:
retriever.retrieve("The godfather is a nice person")
很显然,这次我们的搜索结果的排序颠倒过来了。
自定义过滤器和覆盖查询
llama-index 目前仅支持 ExactMatchFilters。 Elasticsearch 支持多种过滤器,包括范围过滤器、地理过滤器等。 要使用这些过滤器,你可以将它们作为字典列表传递给 es_filter 参数。
def custom_query(query, query_str):print("custom query", query)return queryquery_engine = index.as_query_engine(vector_store_kwargs={"es_filter": [{"match": {"content": "growing up"}}],"custom_query": custom_query,}
)response = query_engine.query("what were his investments in Y Combinator?")
print(response)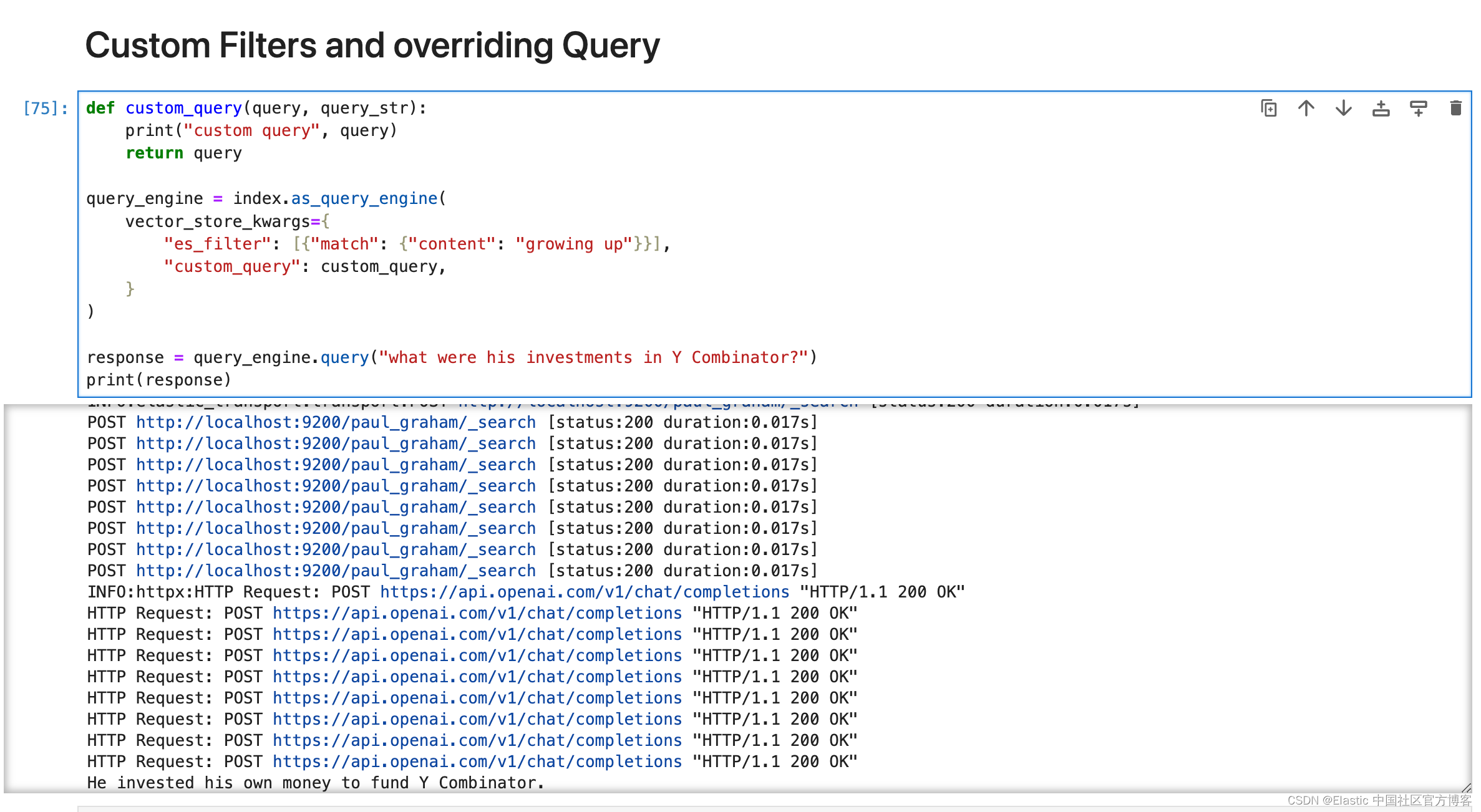
为了方便大家学习,我把所有的源码放到 github:https://github.com/liu-xiao-guo/semantic_search_es。其中相关的文件是:
- https://github.com/liu-xiao-guo/semantic_search_es/blob/main/Elasticsearch%20integration%20-%20LIamaIndex%20.ipynb
更多阅读:使用 Elasticsearch 和 LlamaIndex 进行高级文本检索:句子窗口检索