排名前十的网站网络公司推广方案
一 DML语句读写流程
1 DML语句读流程概要

用户发出SQL
被协议层接收 Protocal Layer
通过PD获取时间戳
parse模块 解析SQL,通过词法解析 与 语法解析 生成AST语法树
编译SQL Compile模块 ,区分点查 与 非点查,生成执行计划 发送给Executor,从TIKV获取数据 返回给用户
2 DML语句读流程概要
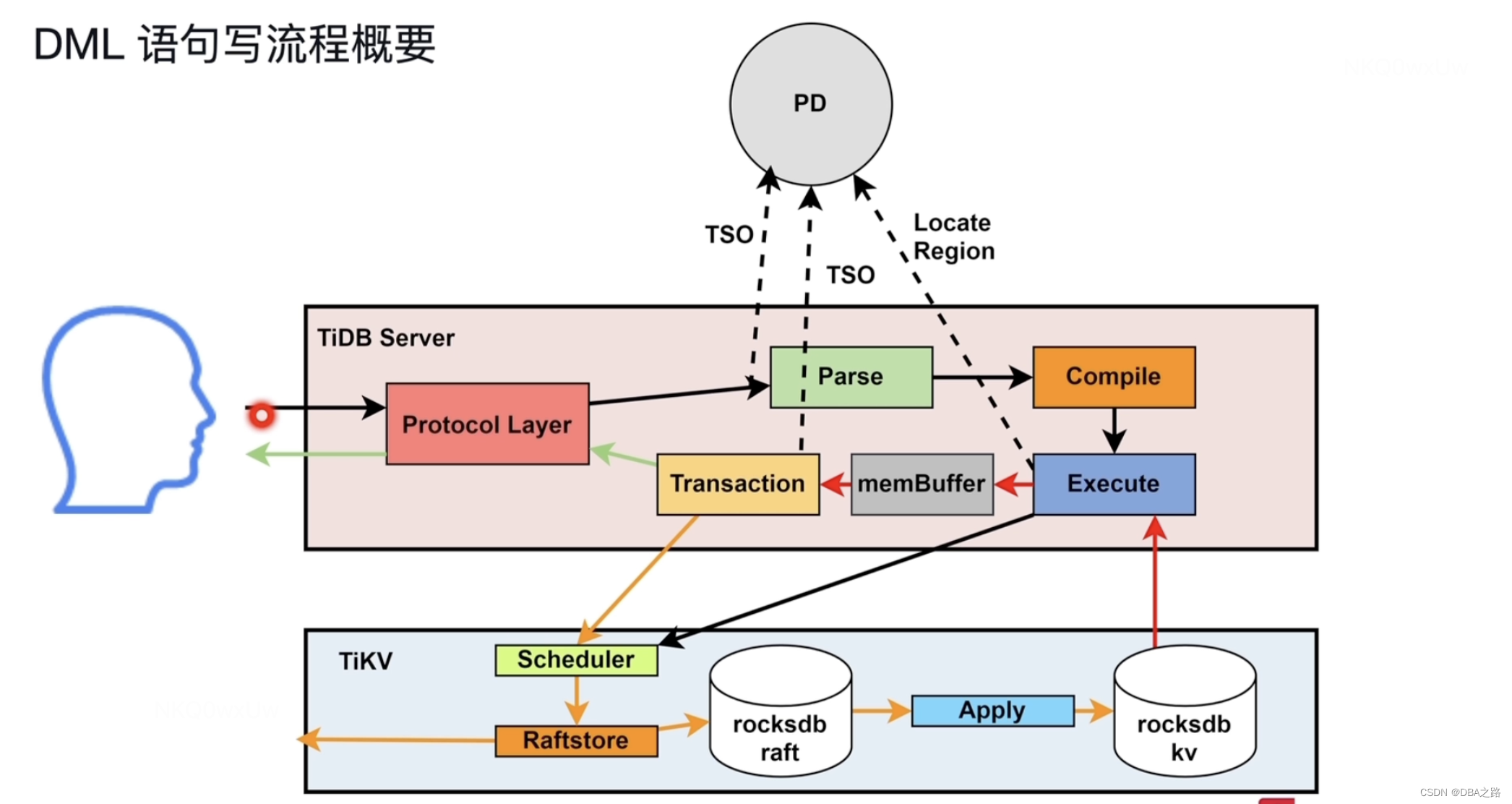
写流程和读流程前面差不多 ,需要先把数据读出来
二 DDL语句的执行流程
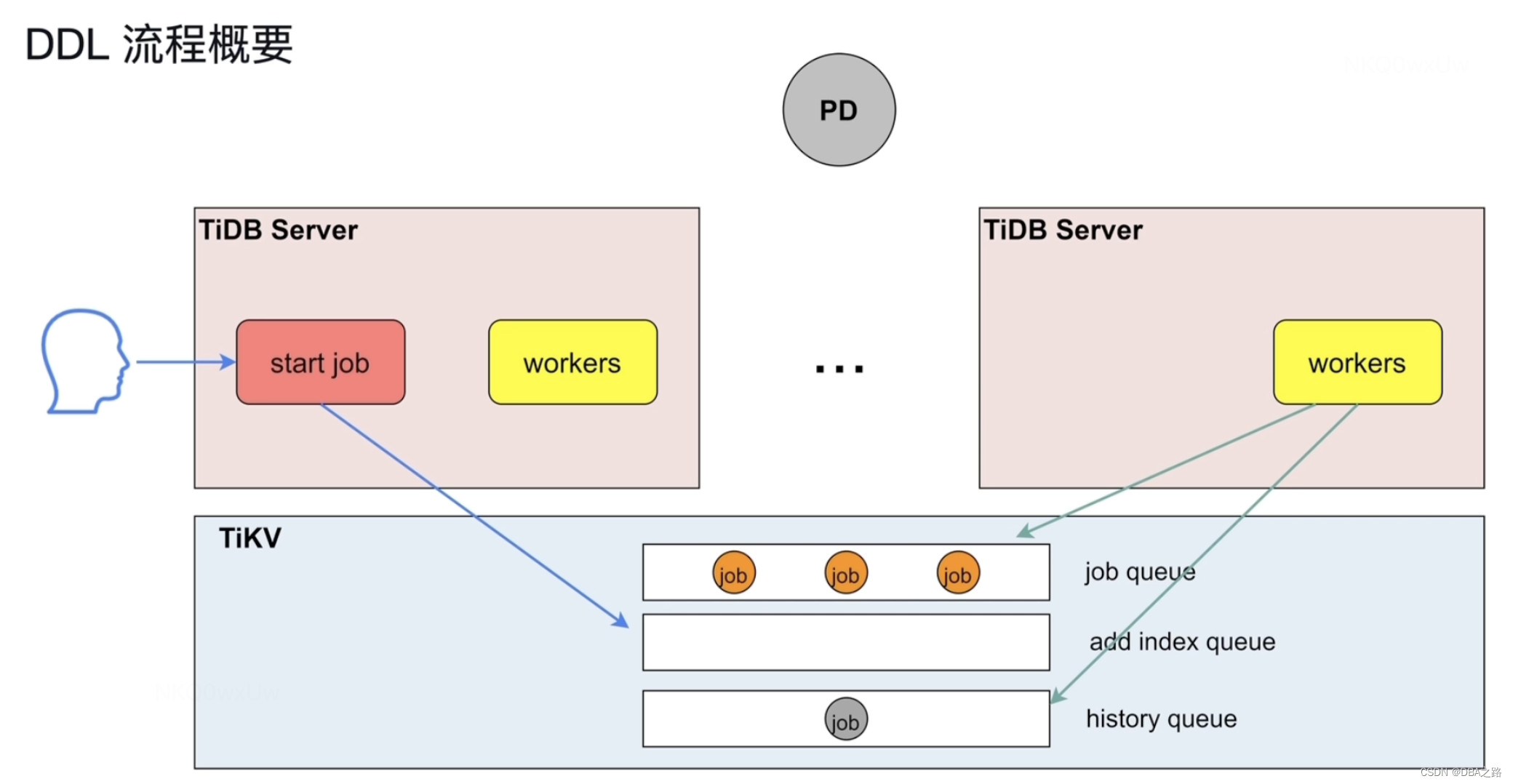
在集群中有多个tidb server .可能有多个DDL 发送到TiDB server上。但是同一时刻只能有一个TiDB server的workers在做DDL
用户发出DDL语句 由模块 start job 模块接收,然后放到job queue队列中。
在同一时刻 只有一个Tidb Server的角色为owner ,owner角色的 Tidb Server的worker才能中从 job queue队列中取DDL,执行完成之后放到history queue中。
owner 角色有任期,并不是固定在一个Tidb Server上。
当成为owner后 ,schema load 会收集所有表的元数据。
队列放到TiKV上主要是为了持久化存储,一旦发生宕机断电可以防止数据丢失。
SQL解析 Parse 与 编译 Compile
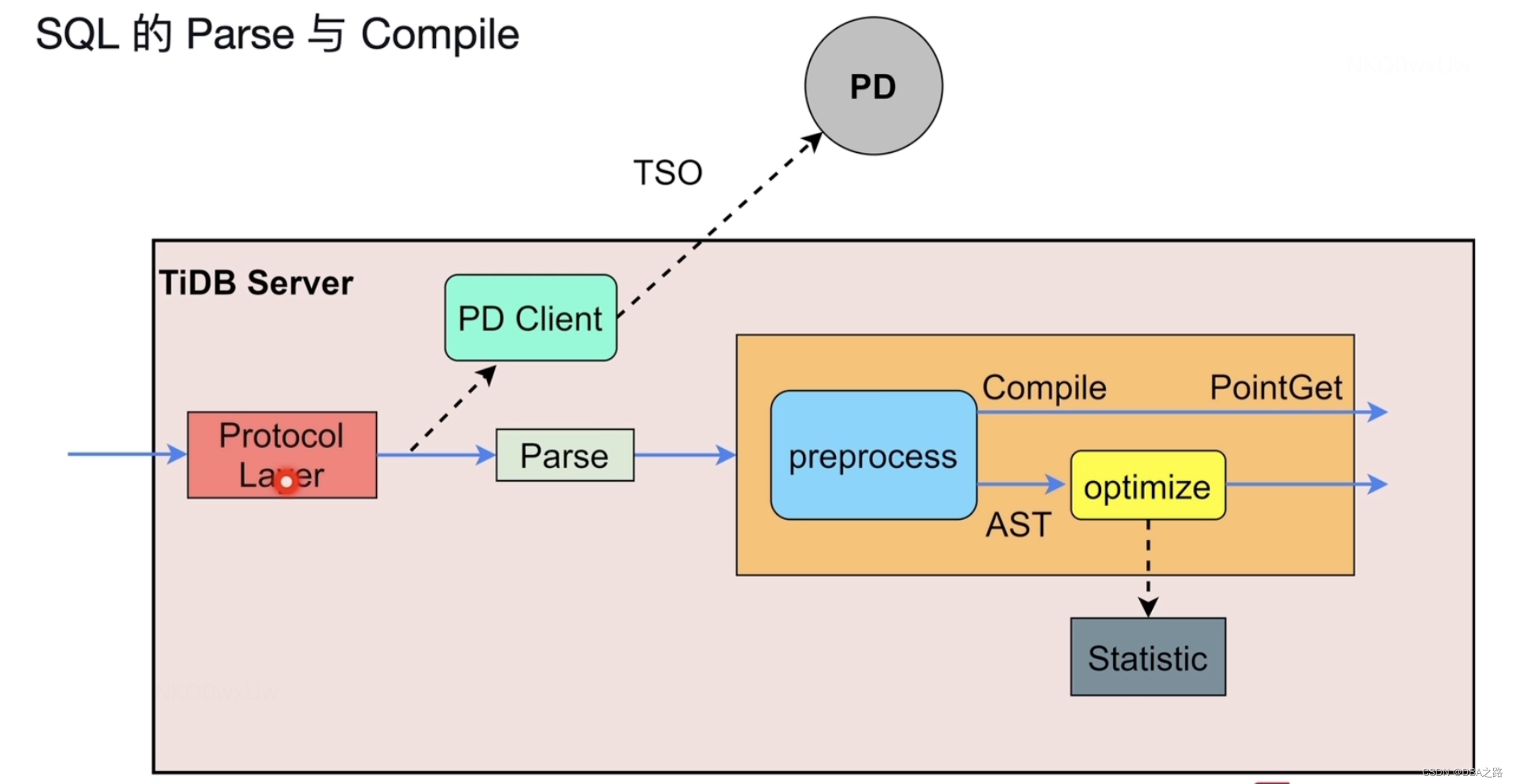
用户发出SQL ,由协议层接收 , PD Client 请求PD 获取TSO ,这条SQL语句起始时间,Parse模块对SQL进行语法解析 词法解析yacc, 转化为AST 语法树,语法树被传递到 Compile模块,细分有三步 1 Proprocess预处理阶段 检测SQL合法性 名称是否正确,绑定的信息等,另外还会 判断是否为点查 (比如通过唯一索引 主键索引的等值查询),这样就不用在走后面的流程,直接执行。如果不是点查 ,则还需要走后面的优化流程,分为逻辑优化 (主要是根据关系代数,等价交换的一些规则对SQL语句进行逻辑的变换,比如外连接转换为内连接),逻辑优化之后就是 物理优化 主要是基于逻辑优化的结果 结合表的统计信息(表的行数,列的选择度 ,直方图等等)选择最优的算子,从Compile模块出来的就是物理执行计划 ,就可以去TiKV中取数。
读取的执行
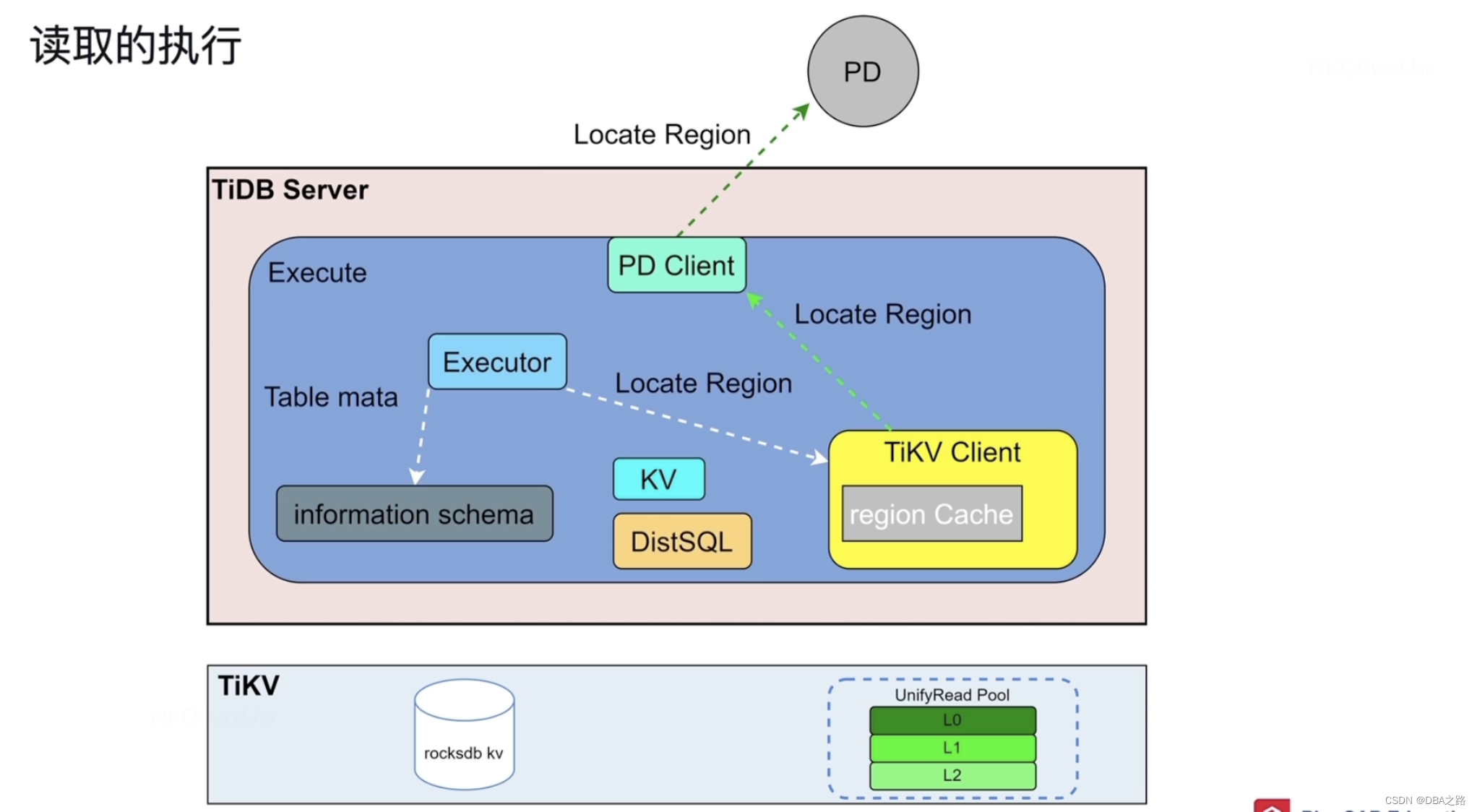
有了执行计划之后 读取的流程 主要设计的模块 在TIDB server中
Executor 执行器
KV 专门负责点查的
DistSQL 执行复杂SQL的
PD Clent 负责与PD沟通
TiKV Client 通过这个出入口与TiKV 交互
Executor 需要做两件事 1 获取元数据,在TIDB 启动的时候 ,information schema是存储了元数据的,已经被载入到Tidb Server的缓存中了,所以直接读缓存就可以了。2 另外还有KEY所在的Region ,Region所在的TiKV等这些信息存储在PD中,所以还需要访问PD,但是TiDB Server 与 PD 是通过网络交互的 ,频繁的交互有很大的网络压力,如何解决 把读取过的信息缓存在TIKV Client的 Region Cache中,下一次再读取相同的Region的时候就去 Region Cache中读取即可。如果存储Region的TIKV发生了变化(region 分裂 合并 过期等) ,根据TIKV Client的 Region Cache的信息就获取不到数据,然后就需要返回,这种现象叫做back Off,出现back Off响应就会延迟, 就会再去PD中读取一次。因为PD中的数据是最新的。
下面就可以去TIKV中读数据了。
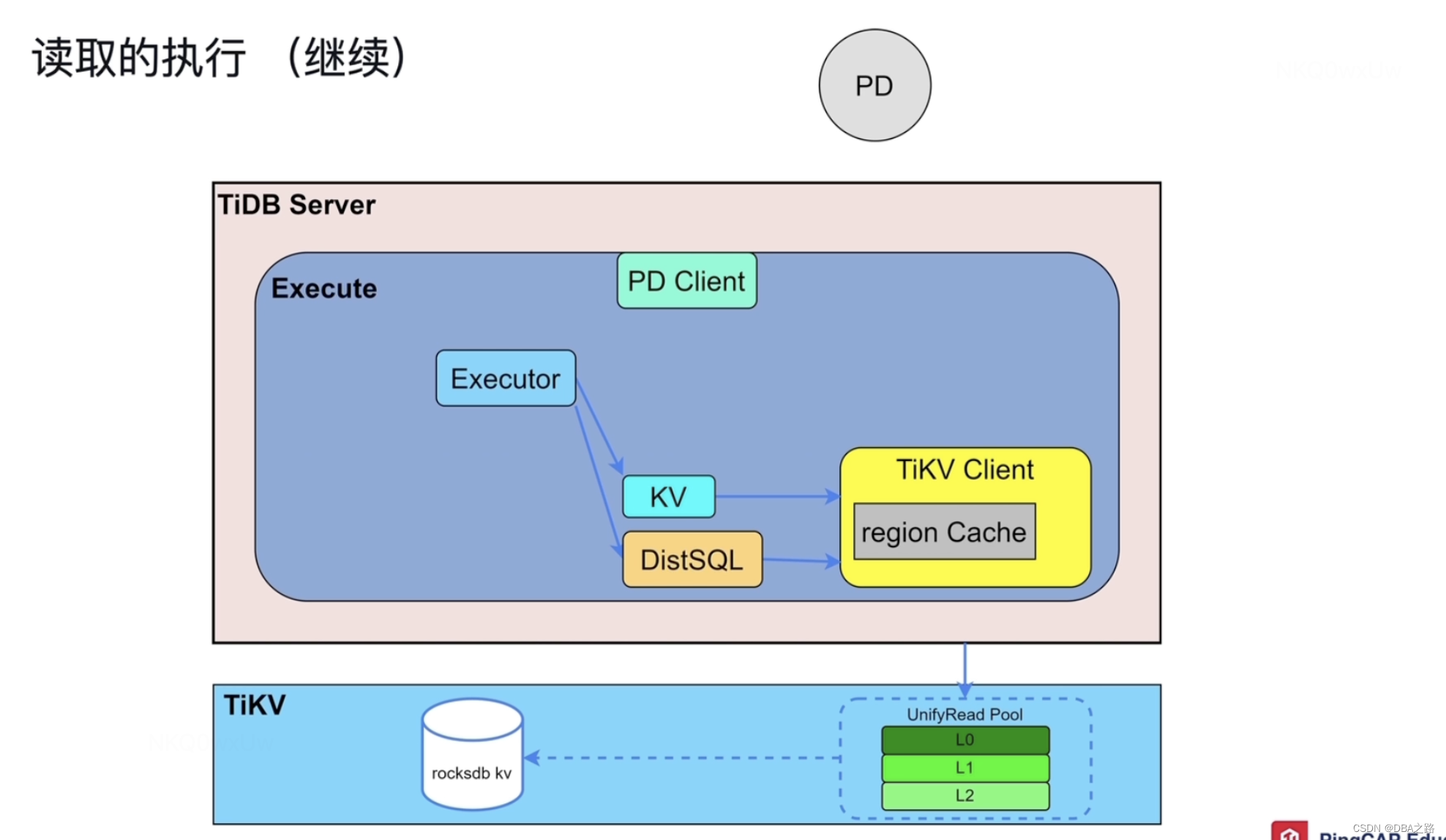
DIstSQL 是一个 抽象层 ,把复杂的SQL语句转换为对单表的简单查询,之后在去下发给TIKV ,这样就相当于吧复杂SQL与TIKV 进行了解耦合。
TIKV接收到SQL请求之后 ,首先会构造一个快照,snapshot,一个特定时间点的数据,比如我十点发出SQL,这样查询的数据永远是十点的。从TIDB 5.0之后无论是点查还是复杂查询 查都会进入到 UnifyRead Pool 线程池 ,按照优先级执行这些查询的 ,然后到rocksdb kv中查询,rocksdb kv的查询也是分层的 由上而下 blockCache -->MEMTable--> Immutable -->MEMTable, 可以参考 【TiDB理论知识 03】TiKV-持久化与数据读取_DBA之路的博客-CSDN博客
这样数据就取出来了。
单表的SQL不一定在一个TIKV上,这个时候可以并行查询 。TIKV 还具有算子下推功能,会帮助TiDB 做数据的过滤和聚合 ,这种叫做 cop task 。还有一部分 TIKV 没有办法 比如做T1 T2 T3表的三表连接 ,数据可能散落在各个TIKV上 ,只能把数据先放到 TIDB的内存中 ,然后再做表连接 ,叫做 root task
写入的执行
需要把修改的数据读入到 membuffer中 ,读入的操作和 之前讲的流程是一样的。咱们从数据已经读入到membuffer中开始 ,
TIDB Server 中 与事务写入的模块主要有三个
Transction
KV
TiKV Client
流程
Transction 进入两阶段提交
TIKV
写请求发送给 Scheduler ,负责协调并发写入的冲突,并将收到的修改操作向下写入,当又并发写入同一个key的时候,用latch 管理冲突 ,谁拿到latch就可以写入
RaftStore 这个模块主要是将写请求转换为Raft log 之后 像两个地方分发 ,持久化到本地,另外向其他副本发送
Apply 线程组 顺序读取这些Raft log 应用到 Rocksdb KV中。
RocksDB 是如何写入 参考
DDL的执行
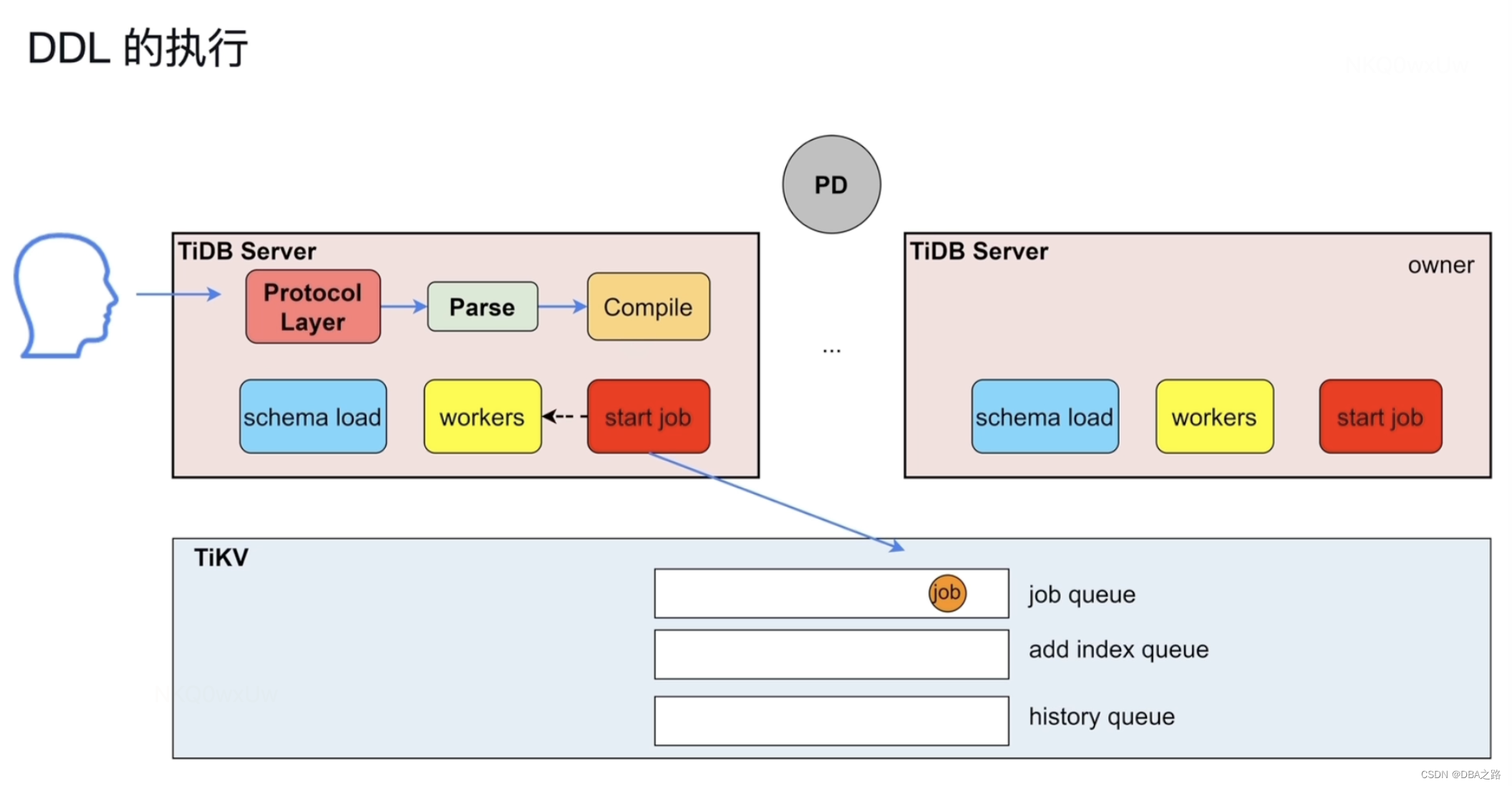
TIDB 支持 online DDL,DDL执行过程中不会阻塞DML的
确定自己是不是owner ,把DDL 放到 TIkV的 job queue队列中 ,角色为owner的TIDB Server会定期查看job queue ,执行完毕后会放到history queue队列中
Owner 角色 是轮循的
add index queue 是个比较特殊的队列 唯独加索引是放到 add index queue 队列中 。加列,修改列的属性都是放到 job queue中
schema load 负责把表的最新的表结构载入到TIDB server 。