网站建设建站基本流程介绍百度霸屏推广靠谱吗
机器学习的分类
一般分为下面几种类别:
监督学习( supervised Learning )
无监督学习( Unsupervised Learning )
强化学习( Reinforcement Learning,增强学习)
半监督学习( Semi-supervised Learning )
深度学习(Deep Learning)
Python Scikit-learn
. http: // scikit-learn.org/ stable/. Machine Leaning in Python
.一组简单有效的工具集
·依赖Python的NumPy ,SciPy和matplotlib库
·开源、可复用
Scikit-learn常用函数
sklearn库介绍
sklearn库
sklearn是scikit-learn的简称,是一个基于Python的第三方模块sklearn库集成了一些常用的机器学习方法,在进行机器学习任务时并不需要实现算法,只需要简单的调用sklearn库中提供的模块就能完成大多数的机器学习任务。
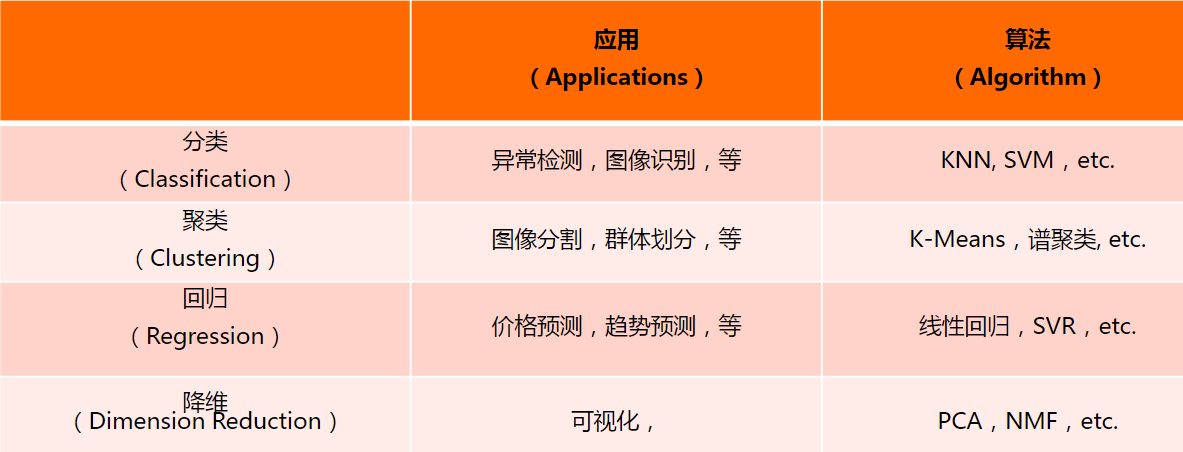
sklearn库是在Numpy、Scipy和matplotlib的基础上开发而成的,因此在介绍sklearn的安装前,需要先安装这些依赖库。
Numpy库
Numpy ( Numerical Python的缩写)是一个开源的Python科学计算库。在Python中虽然提供了list容器和array模块,但这些结构并不适合于进行数值计算,因此需要借助于Numpy库创建常用的数据结构(如∶多维数组,矩阵等)以及进行常用的科学计算(如︰矩阵运算)。
Scipy库是sklearn库的基础,它是基于Numpy的一个集成了多种数学算法和丞数的Python模块。它的不同子模块有不同的应用,如︰积分、插值、优化和信号处理等。
matplotlib是基于Numpy的一套Python工具包,它提供了大量的数据绘图工具,主要用于绘制一些统计图形,将大量的数据转换成更加容易被接受的图表。(注意要先安装numpy再安装matplotlib库)
sklearn库的安装
安装顺序如下∶
1. Numpy库
2. Scipy库
3. matplotlib库
4. sklearn库
依赖库之Numpy的安装
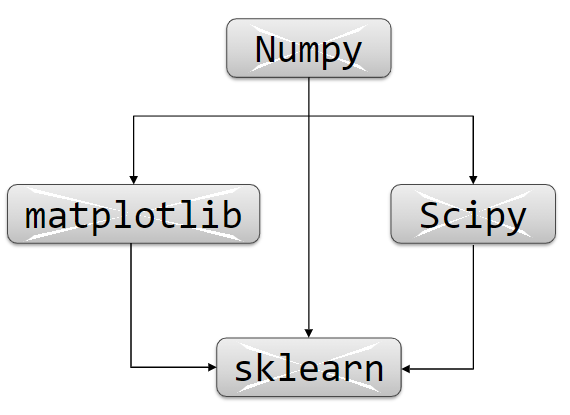
访问Numpy的相关下载链接依据Python的具体版本下载对应的文件。
例如∶本课程使用的是Python3.5的64位版,则下载win_amd64.whl文件。
依赖库之Numpy的安装
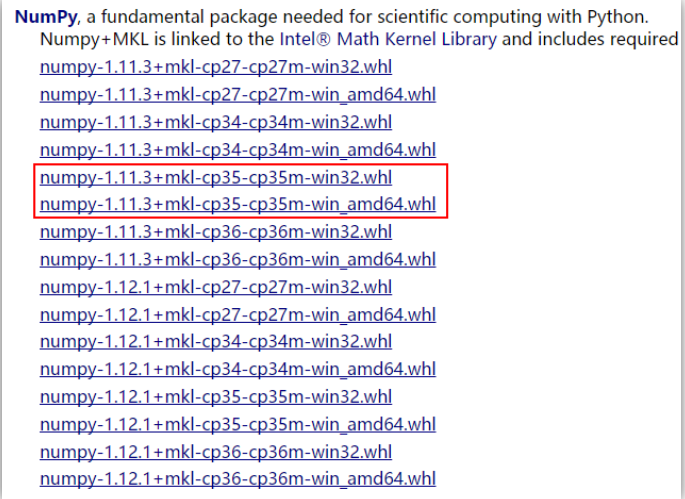
找到下载的文件的路径,打开windows的DOS命令行窗口,执行如下命令∶
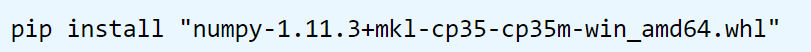

依赖库之Scipy的安装
访scipy的相关下载链接依据Python的具体版本下载对应的文件。同样这里需要下载右侧红框中*win_amd64.whl文件。
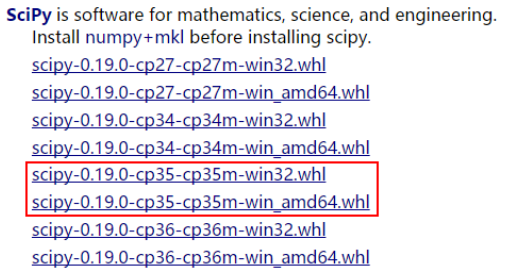
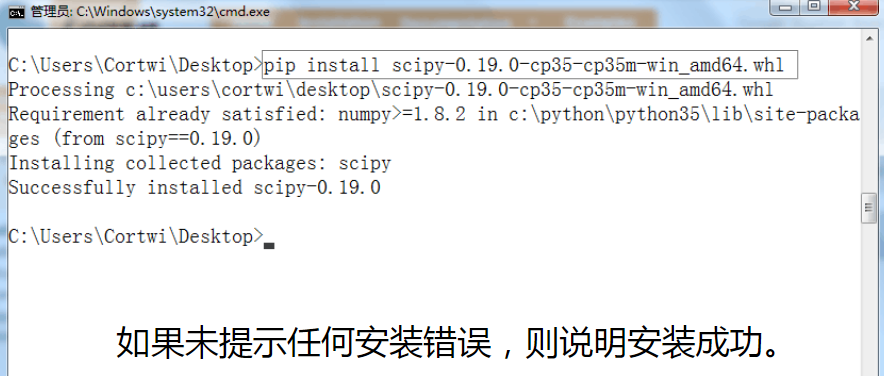
找到下载的文件的路径,打开windows的DOS命令行窗口,使用如下命令∶
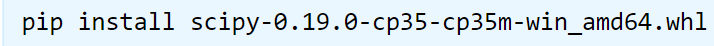
依赖库之matplotlib的安装
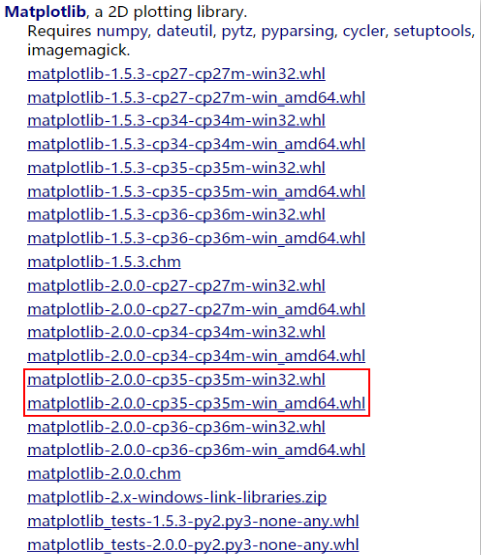
访问matplotlib的相关下载链接
依据Python的具体版本下载对应的文件。下载红框中对应的win_amd64.whl文件。
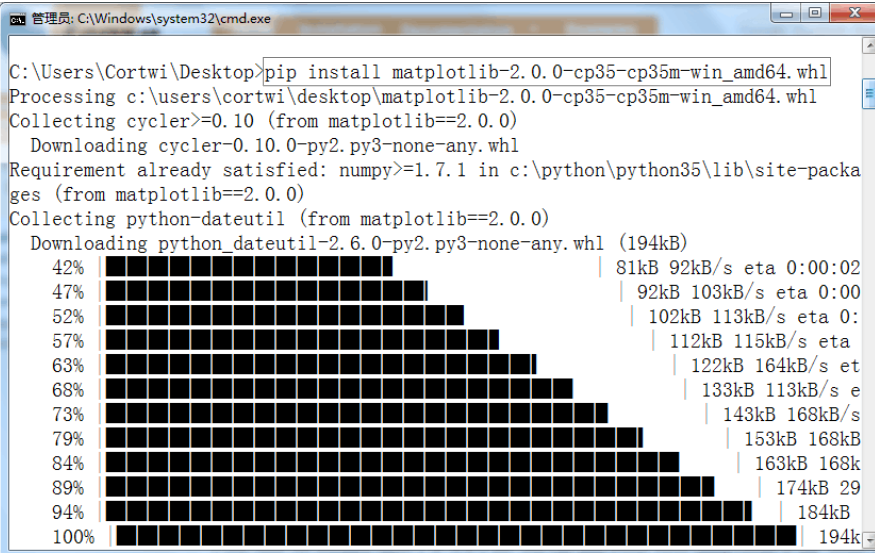
找到下载的文件的路径,打开windows的DOS命令行窗口,使用如下命令∶
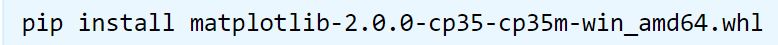
sklearn库的安装
访问sklearn的相关下载链接找到对应的安装文件
同样这里需要下载右侧红框中对应的win_amd64.whl文件。

下载地址: https://pypi.python.org/pypi/scikit-learn/0.18.1
找到下载的文件的路径,打开windows的DOS命令行窗口,使用如下命令∶
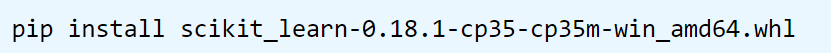

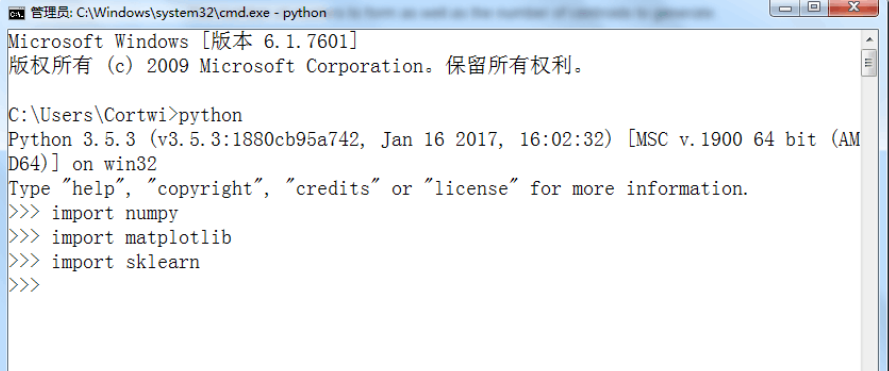
测试
sklearn库中的标准数据集及基本功能
数据集总览
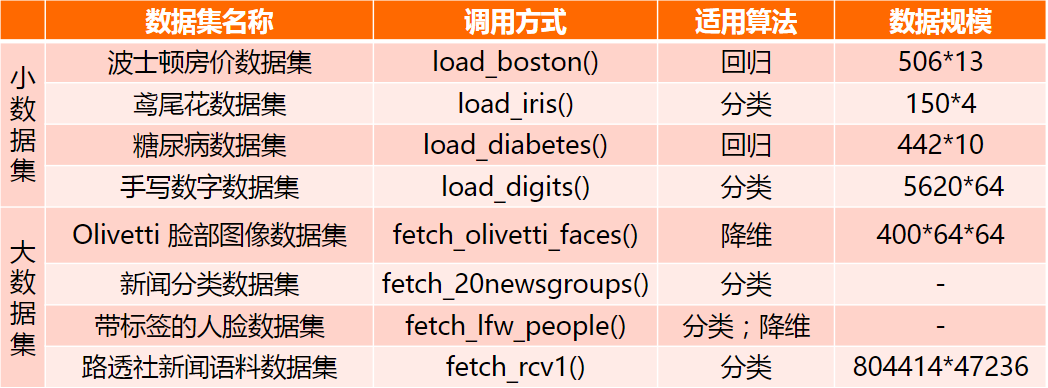
sklearn库的基本功能
sklearn库的共分为6大部分,分别用于完成分类任务、回归任务聚类任务、降维任务、模型选择以及数据的预处理。
分类任务

回归任务
聚类任务
降维任务
无监督学习
利用无标签的数据学习数据的分布或数据与数据之间的关系被称作无监督学习。
有监督学习和无监督学习的最大区别在于数据是否有标签
无监督学习最常应用的场景是聚类(clustering)和降维(DimensionReduction)
聚类
聚类(clustering),就是根据数据的“相似性”将数据分为多类的过程。
评估两个不同样本之间的“相似性”,通常使用的方法就是计算两个样本之间的“距离”。
使用不同的方法计算样本间的距离会关系到聚类结果的好坏。
sklearn.cluster
降维
降维,就是在保证数据所具有的代表性特性或者分布的情况下,将高维数据转化为低维数据的过程∶
数据的可视化精简数据
聚类vs降维
聚类和降维都是无监督学习的典型任务,任务之间存在关联,比如某些高维数据的聚类可以通过降维处理更好的获得,另外学界研究也表明代表性的聚类算法如k-means与降维算法如NMF之间存在等价性
sklearn vs降维
降维是机器学习领域的一个重要研究内容,有很多被工业界和学术界接受的典型算法,截止到目前sklearn库提供7种降维算法。
降维过程也可以被理解为对数据集的组成成份进行分解( decomposition )的过程,因此sklearn为降维模块命名为decomposition,在对降维算法调用需要使用sklearn.decomposition模块